@SPeak 在 rt-thread 双链表分析及教程(附带demo) 中说:
感觉是不是可以拆分一下, 把游戏主体 和 链表实现 分开 用比较项目的目录树风格, 然后放到github上 变成一个Demo项目
这个写法应该不错,博主有没有什么参考的博文推荐,我学习一下他的写法
@SPeak 在 rt-thread 双链表分析及教程(附带demo) 中说:
感觉是不是可以拆分一下, 把游戏主体 和 链表实现 分开 用比较项目的目录树风格, 然后放到github上 变成一个Demo项目
这个写法应该不错,博主有没有什么参考的博文推荐,我学习一下他的写法
@sky-littlestar 在 rt-thread 双链表分析及教程(附带demo) 中说:
其数据结构如下表示(以双链表为例子)
typedef struct DLnode
{
int data; //也可以是其他数据类型
DLnode* next;
DLnode* next;
}DLnode_list;
其数据结构如下表示(以单链表为例子)
typedef struct SLnode
{
int data; //也可以是其他数据类型
SLnode* next;
}SLnode_list;
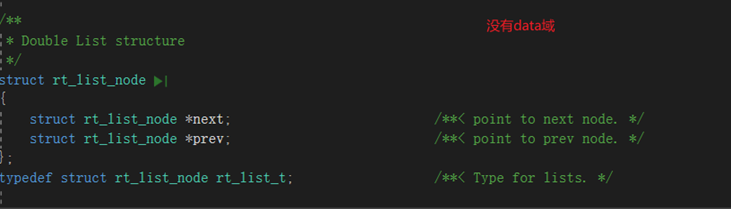
更正一下,上面的图是单链表,我这边改单链表说明一下,原理是一样的。
各位大佬一起来交流,多多指教
本次实验使用的是(Visual Studio 2022,EasyX)文末附完整代码,可直接复制运行
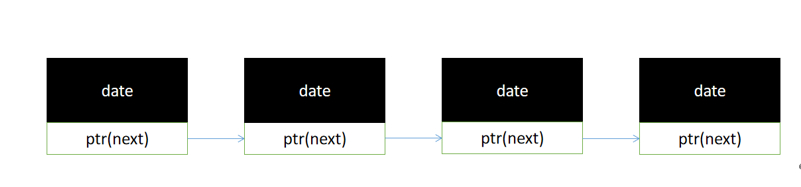
我们平时在进行玩电子游戏时,会发现很多资源都是动态加载的,会不断的生成加载和删除。比如说,我们玩飞机大战时,不同的关卡和地图中,生成的飞机数量是不一样的,然后他被我们的炮弹击落后,飞机的数量又会减少,飞机数量一直处于不确定的状态。我们在玩贪食蛇游戏时,蛇身的长度也是不固定的,蛇吃到食物时,身体会变长,蛇碰到障碍物时,身体会变短,处于一个动态变化的过程。因此,在设计这类动态加载资源的场景是,数组是不太合适的(数组是静态的,在固定初始长度后,不方便扩展),因此,采用链表完成此类应用场景是比较理想的选择。按照传统教科书的教程,我们一般的链表都是一个指针域+一个数据域,通过遍历链表上的每一个节点,得到相关数据。
其数据结构如下表示(以双链表为例子)
typedef struct DLnode
{
int data; //也可以是其他数据类型
DLnode* next;
DLnode* next;
}DLnode_list;
但是,这种固定数据域的方法,并不方便灵活,这要求我们链表上的节点用的都是统一的结构体,由于各个用户对链表数据的需求不同,是没办法直接通过一个统一的API接口,进行链表初始化的。我们可以参考一下rt-thread实时操作系统的做法。把指针域单独提取出来,通过指针域再进行数据域的访问,下面,我们将通过经典的贪食蛇游戏进行示例讲解。
本次实验需要使用到Visual Studio 2022,EasyX图形库。
EasyX的坐标系如下:

贪食蛇需要一个蛇头,还有一段蛇身,其实,每一个蛇的部位,就是一个节点,我们统一用一个结构体进行表示。
enum COMPRESS_E //当前节点的运行方向
{
COMPRESS_UP,
COMPREES_DOWN,
COMPRESS_LEFT,
COMPRESS_RIGHT,
};
typedef struct doublelink_listnode //当前蛇身节点
{
doublelink_listnode* prev;
doublelink_listnode* next;
}Doublelink_listnode;
typedef struct //蛇的节点结构体
{
float x;
float y;
COLORREF color;
COMPRESS_E compass;
Doublelink_listnode node;
}Snake;
这样,我们通过计算蛇的每一个节点的位置,并通过链表将其串联起来,改变链表上节点的位置数据,就是在操纵蛇身的移动。通过增加链表上的节点或者删除链表上的节点,即可以实现蛇身的增长或缩短。首先,我们先初始化一个头节点。
Doublelink_listnode list;
list= Doublelink_Listinit(list);
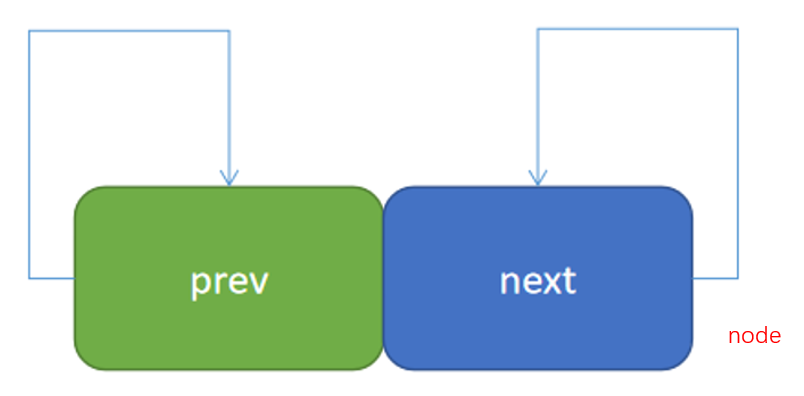
其前驱节点后后继节点均指向自身。
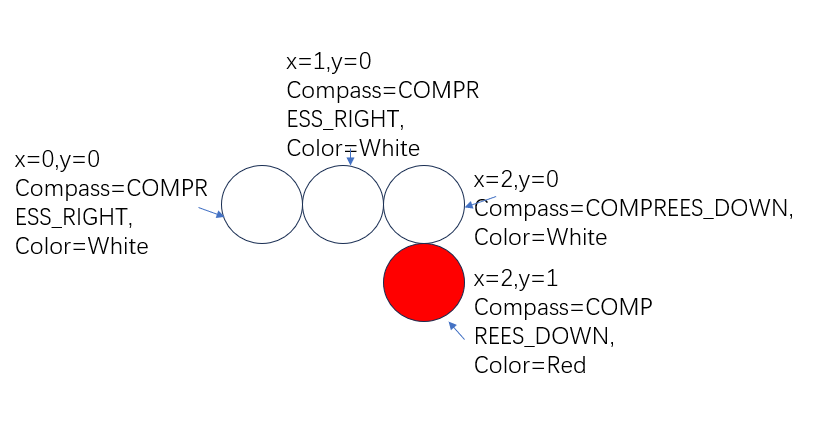
随后,将蛇身插入链表中,我们先初始化6节蛇身,一个圆点表示一段蛇身。
注意,分配空间的时候,要按蛇的整个结构体去分配,不能仅分配Doublelink_listnode node。这是RT-Thread链表和我们平时用的带数据域的链表很大的不同,假如仅分配Doublelink_listnode node,由于该变量的作用域仅在该函数中,当跳转到其他函数时,Snake中的其他数据会被破坏,会导致程序出错。
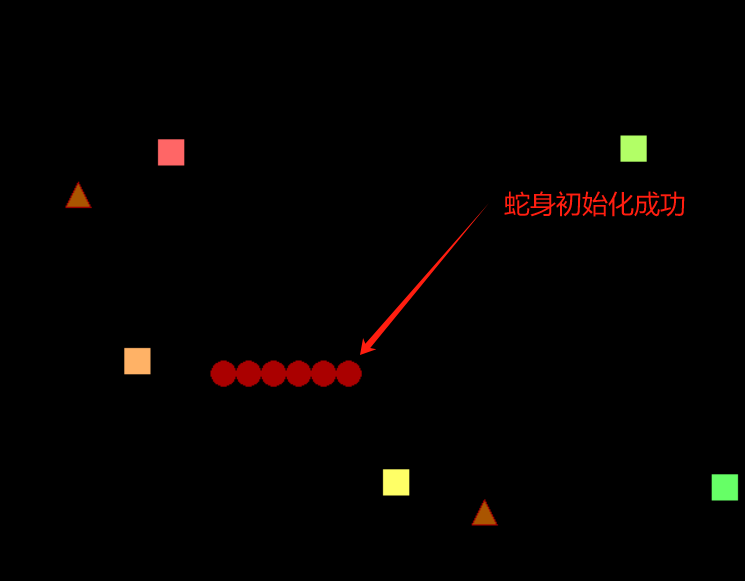
for (int i = 0; i < 6; i++)
{
Snake* snake= (Snake*)malloc(sizeof(Snake));
snake ->x=(i* Radius*2)+100;
snake ->y= 300;
snake->color = RED;
snake->compass = COMPRESS_RIGHT;
doublelink_insertback(&list, &(snake->node)); //将蛇的蛇身插入链表中
}
entrylist_foreach(&list,pos) //遍历6段蛇身,并将其坐标信息以圆圈的形式在图上画出来
{
setlinecolor(list_entry(pos, Snake, node)->color);
setfillcolor(list_entry(pos, Snake, node)->color);
fillcircle(list_entry(pos, Snake, node)->x, list_entry(pos, Snake, node)->y, Radius); //以圆圈的形式画出来
}
通过doublelink_insertback将数据插入链表,然后我们再entrylist_foreach遍历链表,list_entry进入node节点即可得到蛇身的位置,然后利用EasyX在界面上描绘出来,就是我们这个游戏的实现思路。
我们通过一个最小例子,展示一下RT-thread双链表的插入,遍历,读取用法。
分析一下void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node);其函数定义如下:
void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node)
{
node->next = list->next; //1
list->next->prev = node; //2
list->next = node; //3
node->prev = list; //4
}
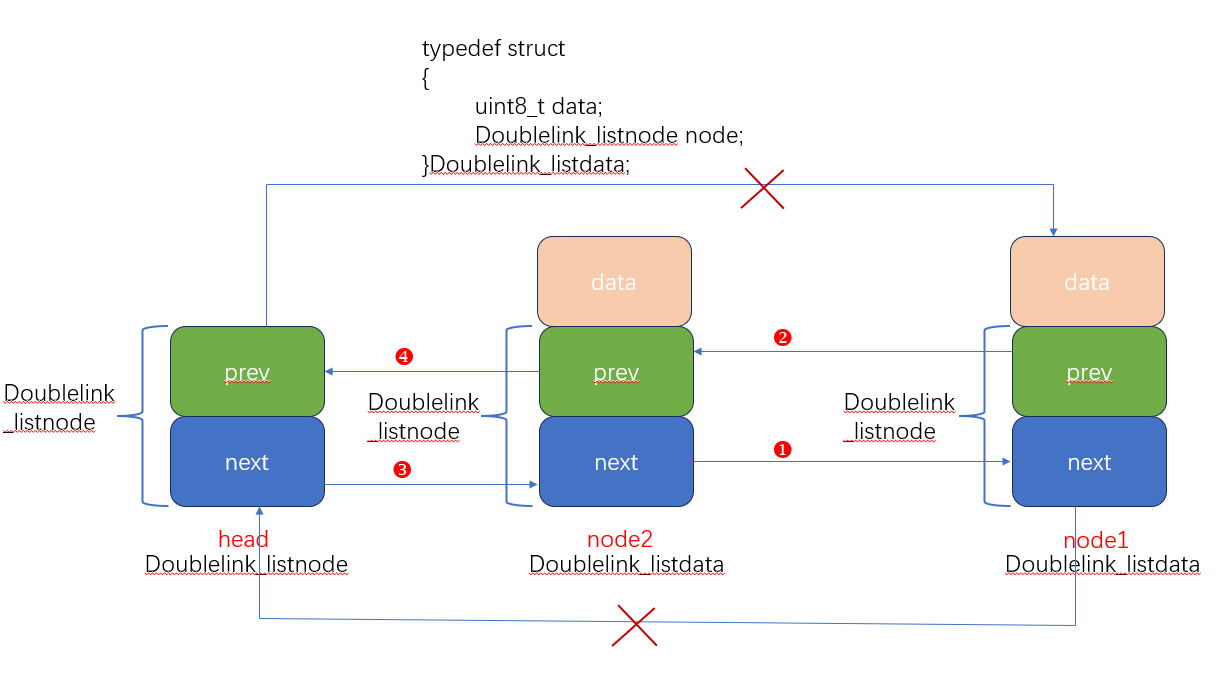
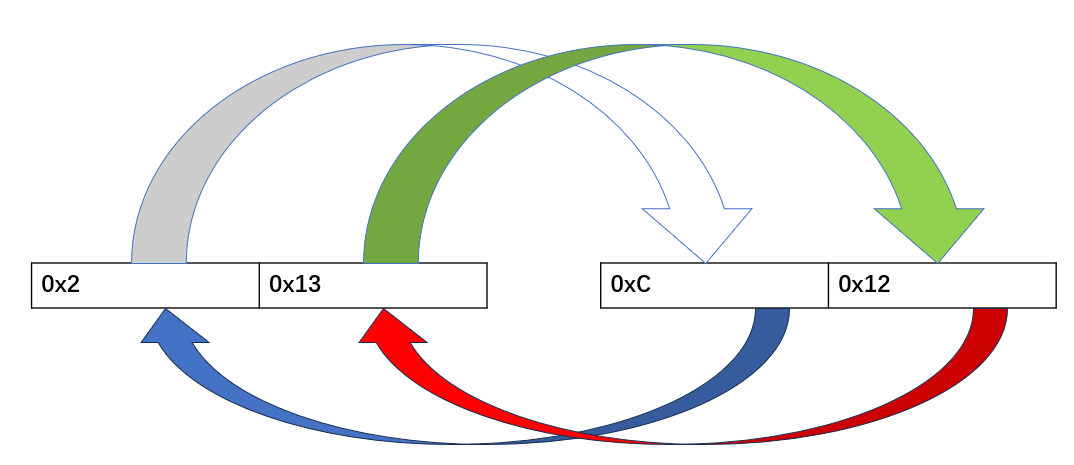
假设之前node1已经插入到链表中,此时我们调用doublelink_insertback(&head, &(node2.node));,将node2插入到链表中,图中分别对应函数中的四个过程:
图中的标号1,对应node->next = list->next;插入node2,node2的next指针指向node1的指针域;
图中的标号2,对应list->next->prev=node,头指针的next对应的是node1,node1的prev指针更新为node2,正如标号2和下面带红色叉号 的箭头所示,head->next的指针被废除,而node2与node1建立起关系,node1->prev=node2;
的箭头所示,head->next的指针被废除,而node2与node1建立起关系,node1->prev=node2;
图中的标号3,对应list->next = node,重新构造list->next指向的地方,如图中上面带红色叉号的箭头所示,head的next指针被重定向,指向node2;
图中的标号4,代表node->prev = list,新插入的node2的prev指针指向head。所以,根据以上的分析我们可以知道,利用doublelink_insertback函数,节点可以插入到链表中,而且,越是后边插入的,当遍历的时候,反而会被优先遍历。
当我们完成链表的插入后,如何遍历链表呢?这个是比较简单的,我们直接通过指针,即可访问各个元素:
#define Doublelink_foreach(list,pos)
for(pos=(&list)->next;pos!=&list;pos=pos->next)
遍历各个元素时,我们还要进入当前节点,读取我们想要的变量
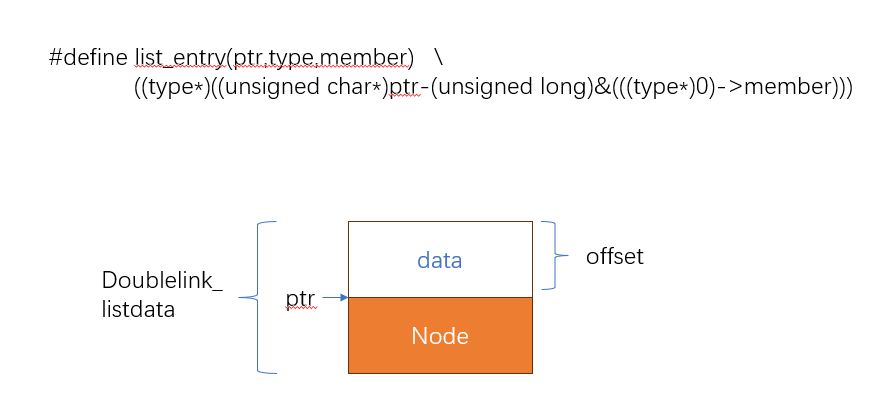
#define list_entry(ptr,type,member)
((type*)((unsigned char*)ptr-(unsigned long)&(((type*)0)->member)))
ptr指的是当前指针指向的位置,type值的是结构体的类型,member是当前指针指向的结构体成员。通过当前指针指向的位置,减去当前指向的成员在结构体中的偏移量,可以知道当前结构体的地址,然后通过指针去访问当前结构体成员可以得到访问变量的值。

下面,运行一个demo展示一下具体用法:
typedef struct Doublelink_listnode
{
Doublelink_listnode* prev;
Doublelink_listnode* next;
}Doublelink_list;
typedef struct
{
uint8_t data;
Doublelink_listnode node;
}Doublelink_listdata;
Doublelink_list head;
Doublelink_list* pos;
#define Doublelink_Listinit(list) {&list,&list}
#define Doublelink_foreach(list,pos) \
for(pos=(&list)->next;pos!=&list;pos=pos->next)
#define list_entry(ptr,type,member) \
((type*)((unsigned char*)ptr-(unsigned long)&(((type*)0)->member)))
void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node);
int main()
{
head=Doublelink_Listinit(head);
Doublelink_listdata node1;
node1.data = 1;
doublelink_insertback(&head, &(node1.node));
Doublelink_listdata node2;
node2.data = 2;
doublelink_insertback(&head, &(node2.node));
Doublelink_listdata node3;
node3.data = 3;
doublelink_insertback(&head, &(node3.node));
Doublelink_foreach(head, pos)
{
printf("%d\r\n", list_entry(pos, Doublelink_listdata, node)->data);
}
}
void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node)
{
node->next = list->next;
list->next->prev = node;
list->next = node;
node->prev = list;
}
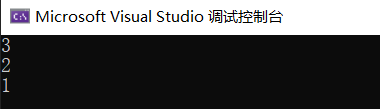
运行结果正确。
蛇身生成完毕,还要生成食物和怪兽,蛇吃到食物后,蛇身会变长,遇到怪兽后,蛇身会变短。
初始化蛇身和怪兽的坐标:
#define Food_Num 5
#define Master_Num 2
for (int i = 0; i < Food_Num; i++)
{
Food_pos[i].x = -1;
Food_pos[i].y = -1;
}
for (int i = 0; i < Master_Num; i++)
{
Master_pos[i].x = -1;
Master_pos[i].y = -1;
}
初始化蛇,食物和怪兽后,调用绘图函数,在界面上根据坐标绘制图形。
cleardevice(); //清空画布
entrylist_foreach(&list,pos) //遍历蛇身,根据蛇身,绘制圆形
{
setlinecolor(list_entry(pos, Snake, node)->color);
setfillcolor(list_entry(pos, Snake, node)->color);
fillcircle(list_entry(pos, Snake, node)->x, list_entry(pos, Snake, node)->y, Radius);
}
for (int i = 0; i < Food_Num; i++) //根据坐标,绘制食物
{
setlinecolor(HSVtoRGB(i * 30, 0.6, 1));
setfillcolor(HSVtoRGB(i * 30, 0.6, 1));
fillrectangle(Food_pos[i].x, Food_pos[i].y, Food_pos[i].x+(2* Radius), Food_pos[i].y + (2 * Radius)); //绘制正方形
}
for (int i = 0; i < Master_Num; i++) //根据坐标,绘制怪兽
{
setlinecolor(RED);
setfillcolor(BROWN);
POINT pts[] = { {Master_pos[i].x, Master_pos[i].y-Radius}, {Master_pos[i].x- Radius, Master_pos[i].y + Radius}, {Master_pos[i].x + Radius, Master_pos[i].y + Radius} }; //绘制三角形
fillpolygon(pts, 3);
}
当资源都加载完毕时,我们可以通过键盘操纵蛇的移动
enum COMPRESS_E
{
COMPRESS_UP,
COMPREES_DOWN,
COMPRESS_LEFT,
COMPRESS_RIGHT,
};
if (_kbhit()) //当探测到键盘输入时
{
char input = _getch();
switch (input)
{
case KEY_UP:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPREES_DOWN)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_UP;
} //按下向上键,当蛇头的移动方向不是向下时,蛇头的移动方向设置为向上
break;
case KEY_DOWN:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_UP)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPREES_DOWN;
} //按下向上键,当蛇头的移动方向不是向上时,蛇头的移动方向设置为向下
break;
case KEY_LEFT:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_RIGHT)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_LEFT;
} //按下向上键,当蛇头的移动方向不是向右时,蛇头的移动方向设置为向左
break;
case KEY_RIGHT:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_LEFT)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_RIGHT;
} //按下向上键,当蛇头的移动方向不是向左时,蛇头的移动方向设置为向右
break;
}
if (gamestatus == -1)
{
start_up(); //当游戏为结束状态时,按下任意键,重启
}
}
#define list_entry_firstnode(list,type,member)
((type*)((char*)((list)->next)-(unsigned long)(&((type*) 0)->member)))
进入链表的第一个节点,可以直接求出蛇头。
if (list_entry_firstnode(&list, Snake, node)->x >= WindowWidth|| list_entry_firstnode(&list, Snake, node)->x <= 0\
|| list_entry_firstnode(&list, Snake, node)->y <= 0|| list_entry_firstnode(&list, Snake, node)->y>=WindowHeight\
|| doublelink_nodenum(&list) < 2
)
{
entrylist_foreach(&list, pos)
list_entry(pos, Snake, node)->color = GREEN;
gamestatus = -1; //碰撞检测,当蛇头到达界面的边缘时,游戏结束
}
entrylist_foreach((&list)->next, pos)
{
if (list_entry(pos, Snake, node)->x == list_entry_firstnode(&list, Snake, node)->x && list_entry(pos, Snake, node)->y == list_entry_firstnode(&list, Snake, node)->y)
{
gamestatus = -1; //碰撞检测,当蛇头与其他蛇身部位碰撞时,游戏结束
}
}
list_entry_firstnode(&list, Snake, node)->x += dirs[list_entry_firstnode(&list, Snake, node)->compass][0] * Speed*2;
//结合移动方向和速度更新蛇头的x坐标
list_entry_firstnode(&list, Snake, node)->y += dirs[list_entry_firstnode(&list, Snake, node)->compass][1] * Speed*2;
//结合移动方向和速度更新蛇头的y坐标
entrylist_foreach(&list,pos)
{
if (pos->next != (&list)) //更新蛇身各段的坐标
{
list_entry(pos->next, Snake, node)->x = list_entry(pos, Snake, node)->x - dirs[list_entry(pos, Snake, node)->compass][0] * Radius * 2;
list_entry(pos->next, Snake, node)->y = list_entry(pos, Snake, node)->y - dirs[list_entry(pos, Snake, node)->compass][1] * Radius * 2;
}
}
for (pos = (&list)->prev; pos != &list; pos = pos->prev)
{
if (pos != (&list)->next) //更新蛇身各段的移动方向
list_entry(pos, Snake, node)->compass = list_entry(pos->prev, Snake, node)->compass;
}
蛇的身体各段坐标计算方法如下:
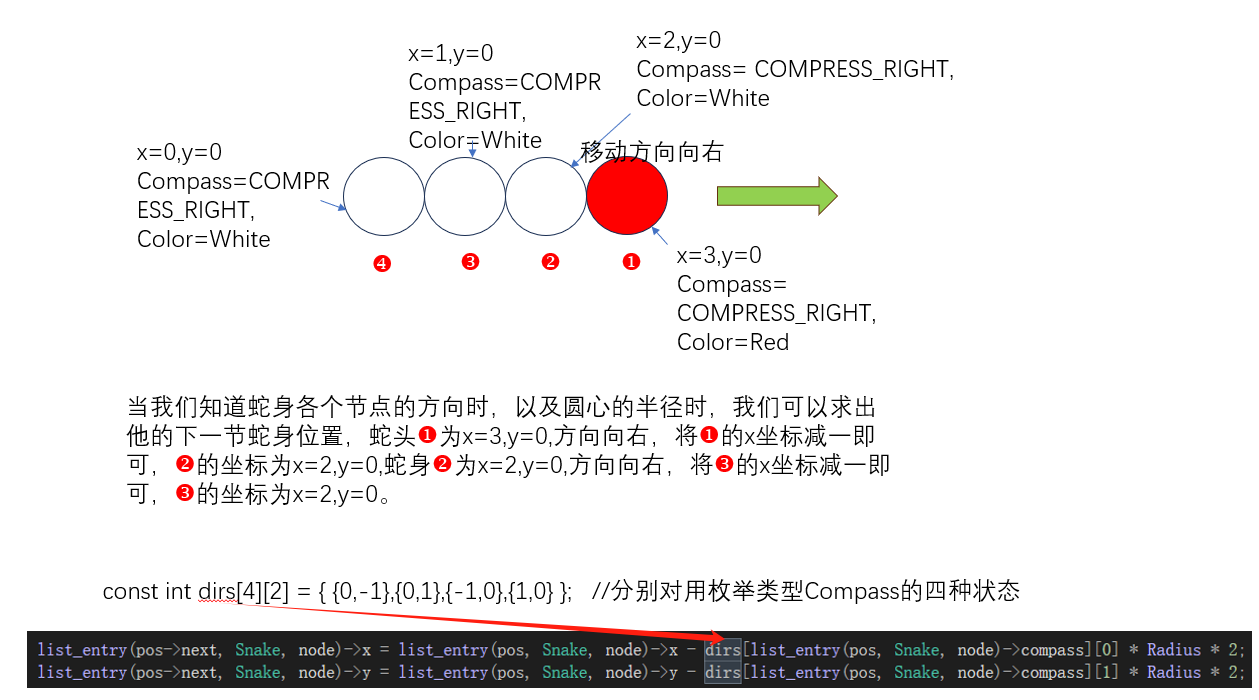
当此时接收到键盘来的指令向下时,蛇头的运动方向变为向下,随后更新蛇的各个节点坐标。
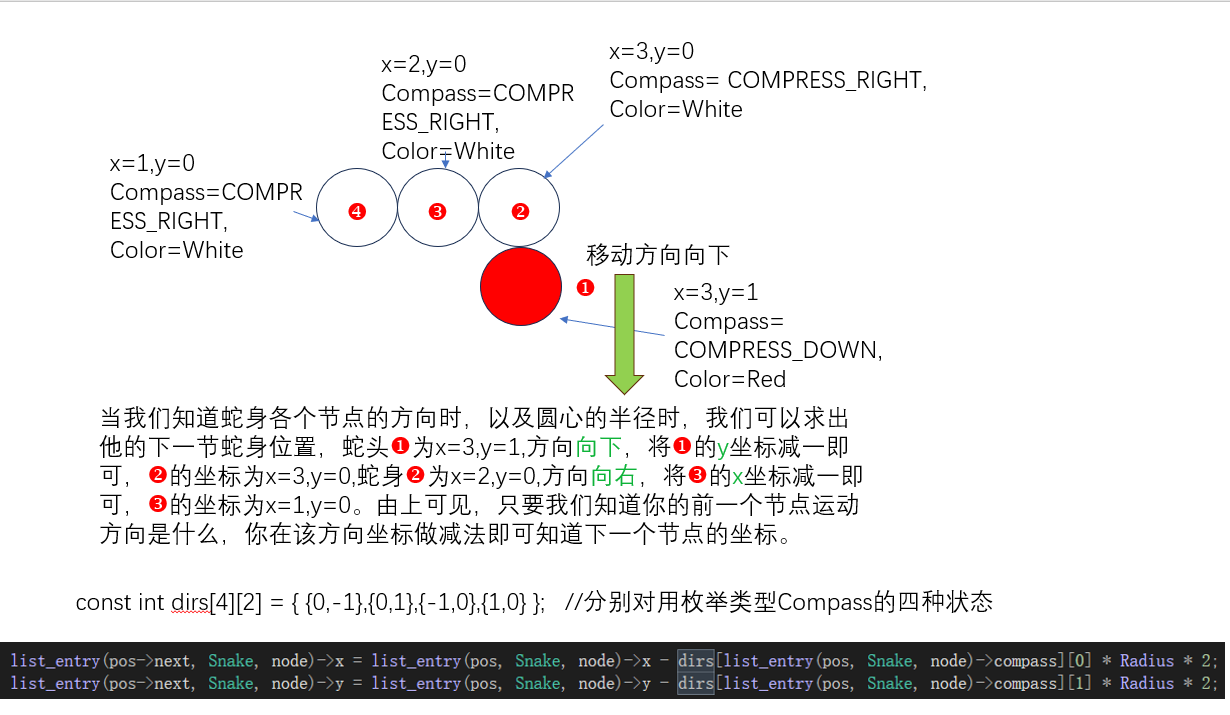
随后,由于你的蛇头运动方向已经更改,所以蛇身的各个方向也会随着变化,后一个节点的运动方向将会继承前一个节点。

所以蛇身的轨迹更新模块,我们已经完成。
下面还需要一些事件更新模块,比如说,蛇吃到食物,蛇身会变长,蛇遇到怪兽,蛇身会变短。
void snake_eatfood(void) //蛇吃到食物
{
for (int i = 0; i < Food_Num; i++)
{
if ((list_entry_firstnode(&list, Snake, node)->x) >= Food_pos[i].x- Radius && (list_entry_firstnode(&list, Snake, node)->x) <= Food_pos[i].x + 3 * Radius &&\
(list_entry_firstnode(&list, Snake, node)->y) >= Food_pos[i].y- Radius && (list_entry_firstnode(&list, Snake, node)->y) <= Food_pos[i].y + 3 * Radius \
) //坐标检测,由于食物占用一定空间,当蛇头的坐标与食物的坐标距离在一定范围内,认为蛇吃到食物
{
Food_pos[i].x = -1;
Food_pos[i].y = -1;
Snake* snake = (Snake*)malloc(sizeof(Snake));
snake->color = GREEN;
snake->compass = list_entry((&list)->prev,Snake,node)->compass;
doublelink_inserttop(&list,&(snake->node));
return; //分配更多的节点,蛇身边长,这次是doublelink_inserttop,将节点加到蛇尾后边,分析方法跟之前insertback一样
}
}
}
void food_generate(void) //生成食物
{
int count = 0;
int index[Food_Num];
for (int i = 0; i < Food_Num; i++)
{
if ((Food_pos[i].x == -1 && Food_pos[i].y == -1)) //当食物坐标为x=-1,y=-1时,证明没有加载,需要生成
{
index[count]=i;
count++;
}
}
while(count) //生成一定数量的食物,生成完退出
{
uint16_t x_rand = rand() % (WindowWidth - 2* Radius);
uint16_t y_rand = rand() % (WindowHeight - 2 * Radius);
int pos_legal = 1;
for (int i = 0; i < Food_Num; i++)
{
if ((Food_pos[i].x == x_rand && Food_pos[i].y == y_rand)) //假如新生成的食物坐标,与现有的食物重叠,判定不合法,重新生成
{
pos_legal = 0;
break;
}
}
for (int i = 0; i < Master_Num; i++) //假如新生成的食物坐标,与现有的怪兽坐标重叠,判定不合法,重新生成
{
if (Master_pos[i].x == x_rand && Master_pos[i].y == y_rand)
{
pos_legal = 0;
break;
}
}
if (pos_legal) //合法食物坐标,可以生成
{
Food_pos[index[count-1]].x = x_rand;
Food_pos[index[count-1]].y = y_rand;
count--;
}
}
}
void snake_acrossmaster(void)
{
for (int i = 0; i < Master_Num; i++)
{
if ((list_entry_firstnode(&list, Snake, node)->x) >= Master_pos[i].x - Radius && (list_entry_firstnode(&list, Snake, node)->x) <= Master_pos[i].x + Radius \
&& (list_entry_firstnode(&list, Snake, node)->y) >= Master_pos[i].y - Radius && (list_entry_firstnode(&list, Snake, node)->y) <= Master_pos[i].y + Radius
) //坐标检测,由于怪兽占用一定空间,当蛇头的坐标与怪兽的坐标距离在一定范围内,认为蛇遇到怪兽
{ //撞到怪兽,每次减少两节蛇身,前面的代码我们判定,当蛇身小于2节时,游戏结束,所以来到这里,蛇身是大于2节的,能够删除
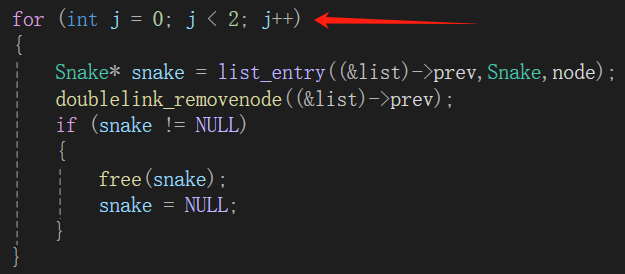
for (int j = 0; j < 2; j++)
{
Snake* snake = list_entry((&list)->prev,Snake,node);
doublelink_removenode((&list)->prev); //移除节点
if (snake != NULL)
{
free(snake); //释放内存
snake = NULL;
}
}
Master_pos[i].x = -1;
Master_pos[i].y = -1;
}
}
}
void generate_master(void) //生成怪兽
{
uint8_t count = 0;
int index[Master_Num];
for (int i = 0; i < Master_Num; i++) //当怪兽坐标为x=-1,y=-1时,证明没有加载,需要生成
{
if (Master_pos[i].x == -1 && Master_pos[i].y == -1)
{
index[count] = i;
count++;
}
}
while (count)
{
uint8_t poslegal=1;
uint16_t x_pos = Radius + rand() % (WindowWidth - 2 * Radius);
uint16_t y_pos = Radius + rand() % (WindowHeight - 2 * Radius);
for (int i = 0; i < Master_Num; i++) //假如新生成的怪兽坐标,与现有的怪兽重叠,判定不合法,重新生成
{
if (Master_pos[i].x == x_pos && Master_pos[i].y == y_pos)
{
poslegal = 0;
break;
}
}
for (int i = 0; i < Food_Num; i++) //假如新生成的怪兽坐标,与现有的食物重叠,判定不合法,重新生成
{
if (Food_pos[i].x == x_pos && Food_pos[i].y == y_pos)
{
poslegal = 0;
break;
}
}
if (poslegal) //合法怪兽坐标,可以生成
{
Master_pos[index[count-1]].x = x_pos;
Master_pos[index[count-1]].y = y_pos;
count--;
}
}
}
至此,我们已经介绍完蛇身的坐标计算方法,食物的生成方法,蛇身的增长方法,怪兽的生成方法,已经遇到怪兽蛇身变短的计算方法。游戏基本运行逻辑已经建立起来。但是,我们前面说过,当蛇撞到墙(界面边缘)也会死去,触发游戏结束界面,此时,我们也应该把蛇的节点全部去掉,为下一轮游戏重启做准备。于是,我又添加了以下逻辑:
if (gamestatus == -1)
{
settextstyle(WindowHeight/ 20, 0, _T("宋体")); // 设置文字大小、字体
// 设定文字颜色,不同数值,颜色不同
settextcolor(RGB(120, 120, 120));
RECT r = { 0,0,WindowWidth,WindowHeight };
if (gamestatus == -1)
drawtext(_T("游戏失败,按任意键重新开始"), &r, DT_CENTER | DT_VCENTER | DT_SINGLELINE);
else if (gamestatus == 1)
drawtext(_T("游戏胜利,按任意键重新开始"), &r, DT_CENTER | DT_VCENTER | DT_SINGLELINE);
if (!doublelink_isempty(&list))
{
Doublelink_listnode* temp = NULL;
entrylist_foreach_safe(&list, pos, temp) //安全遍历链表
{
doublelink_removenode(pos); //删除节点
Snake* snake = list_entry(pos, Snake, node);
if (snake != NULL)
{
free(snake); //释放空间
snake = NULL;
}
}
temp = NULL;
}
}
值得注意的是,这里删除节点的遍历方法和之前的遍历方法不一样。
我们引入了安全遍历,entrylist_foreach_safe(&list, pos, temp);
#define entrylist_foreach_safe(head,pos,temp)
for(pos=(head)->next,temp=pos->next;pos!=head;pos=temp,temp=pos->next)
安全遍历与普通遍历相比,多了temp,记录将要遍历的下一个节点,假如我们利用普通遍历,删除节点的时候不记录下一个节点的方向,释放当前节点pos后,将无法进行下一步寻址。
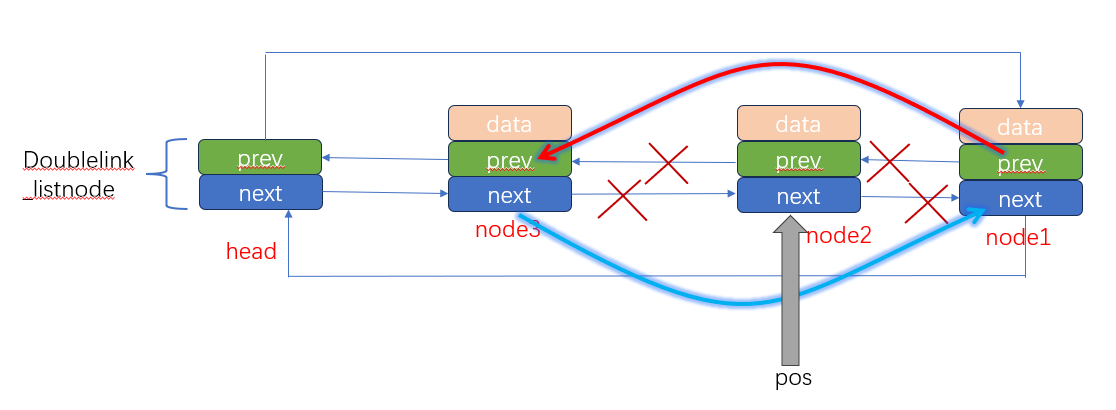
假设,此时调用,doublelink_removenode(pos);
void doublelink_removenode(Doublelink_listnode* node)
{
node->prev->next = node->next;
node->next->prev = node->prev;
node->next = node;
node->prev = node;
}
如上图所示,node2的前节点node3和后节点node1将会建立联系,node3->next=node1;node1->prev=node3;
但是,经过这一步操作后,node2将会成为一个孤立的节点,他的next和prev将会指向自己。我们将无法通过node2找到他的下一个节点node1。
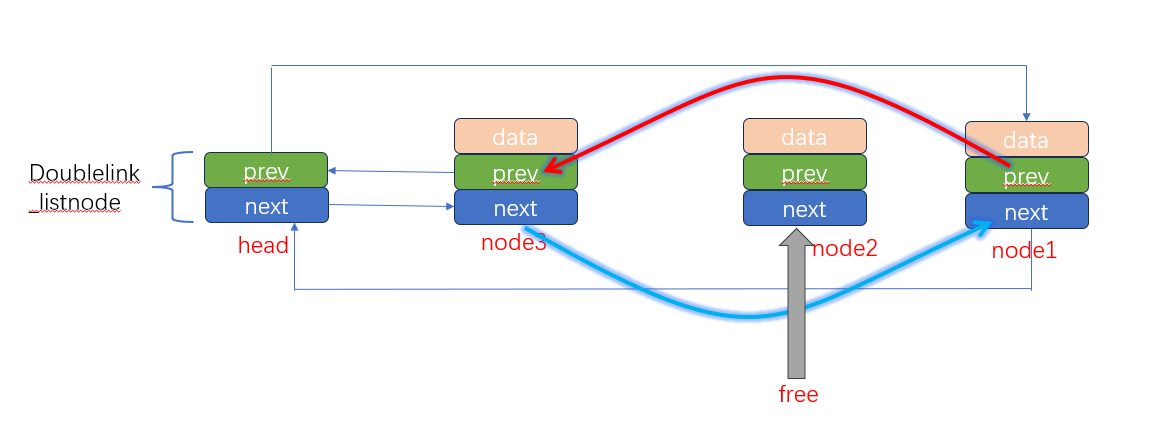
当我们此时调用for(pos=(head)->next;pos!=(head);pos=pos->next),由于找不到pos->next所以会直接导致死机。
而我们采用安全遍历,for(pos=(head)->next,temp=pos->next;pos!=head;pos=temp,temp=pos->next)可以有效地避免这一个问题。
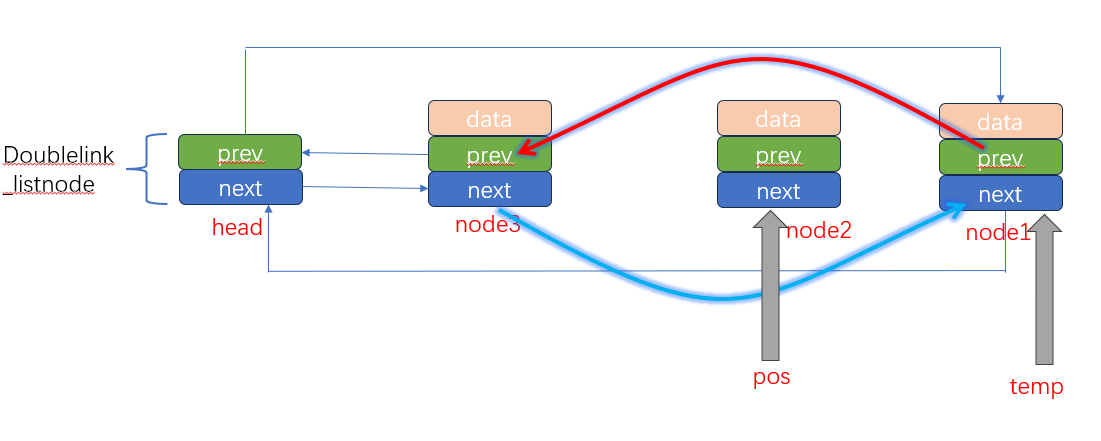
我们的创建一个指针temp,指向当前节点pos的下一个节点,假如我们执行doublelink_removenode时要移除pos时,由于我们已经保存了temp,我们下一轮直接读取temp,我们也可以进入到下一个节点。
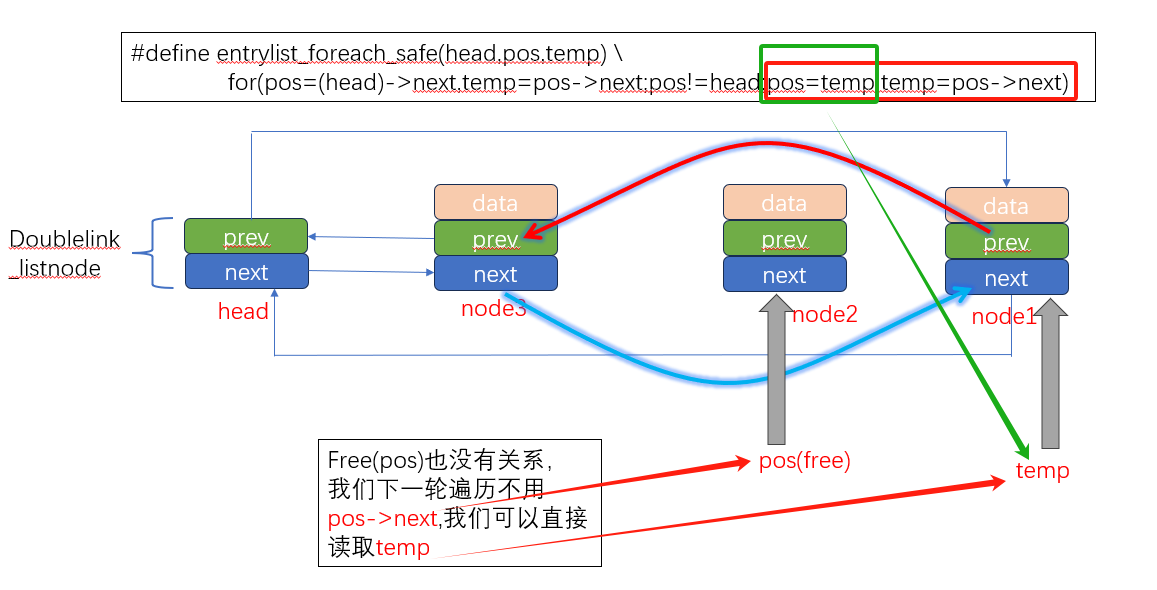
至于我们之前蛇碰到食物时,为啥不用安全遍历,因为我们当时删除蛇身,不是用遍历链表的方法,而是用循环,直接找到尾节点删除的。
至此,我们游戏的各个模块都已经搭建完毕,下面我直接贴出运行代码,读者可以下载Easy X图形库,复制代码到VS 2022平台,直接运行,体验游戏。
#include <stdio.h>
#include <stdlib.h>
#include<time.h>
#include<stdint.h>
#include<graphics.h>
#include<conio.h>
#include<assert.h>
#include<math.h>
#include<string.h>
#include<time.h>
#define WindowWidth 600
#define WindowHeight 500
#define Radius 10
#define Speed 10
#define Food_Num 5
#define Master_Num 2
#define ROWNUM 50
#define COLNUM 60
#define KEY_UP 72
#define KEY_DOWN 80
#define KEY_LEFT 75
#define KEY_RIGHT 77
#define Doublelink_Listinit(list) {&list,&list}
#define list_entry(ptr,type,member) \
((type*)((char*)(ptr)-(unsigned long)(&((type*) 0)->member)))
#define list_entry_firstnode(list,type,member)\
((type*)((char*)((list)->next)-(unsigned long)(&((type*) 0)->member)))
#define entrylist_foreach(head,pos) \
for(pos=(head)->next;pos!=(head);pos=pos->next)
#define entrylist_foreach_safe(head,pos,temp) \
for(pos=(head)->next,temp=pos->next;pos!=head;pos=temp,temp=pos->next)
enum COMPRESS_E
{
COMPRESS_UP,
COMPREES_DOWN,
COMPRESS_LEFT,
COMPRESS_RIGHT,
};
typedef struct doublelink_listnode
{
doublelink_listnode* prev;
doublelink_listnode* next;
}Doublelink_listnode;
typedef struct
{
float x;
float y;
COLORREF color;
COMPRESS_E compass;
Doublelink_listnode node;
}Snake;
typedef struct
{
int x;
int y;
}Coordinate;
const int dirs[4][2] = { {0,-1},{0,1},{-1,0},{1,0} };
Coordinate Food_pos[Food_Num];
Coordinate Master_pos[Master_Num];
Doublelink_listnode list;
Doublelink_listnode* pos=NULL;
int gamestatus = 0;
void start_up(void);
void show(void);
void update(void);
void food_generate(void);
void generate_master(void);
void snake_eatfood(void);
void snake_acrossmaster(void);
void doublelink_listinit(doublelink_listnode* list);
void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node);
void doublelink_inserttop(Doublelink_listnode* list, Doublelink_listnode* node);
void doublelink_removenode(Doublelink_listnode* node);
int doublelink_isempty(Doublelink_listnode* list);
uint8_t doublelink_nodenum(const Doublelink_listnode* list);
int main()
{
start_up();
while (1)
{
show();
update();
}
_getch();
return 1;
}
void start_up(void)
{
srand((unsigned)time(NULL));
initgraph(WindowWidth, WindowHeight);
BeginBatchDraw();
setbkcolor(RGB(0, 0, 0));
cleardevice();
gamestatus = 0;
list= Doublelink_Listinit(list);
for (int i = 0; i < 6; i++)
{
Snake* snake= (Snake*)malloc(sizeof(Snake));
snake ->x=(i* Radius*2)+100;
snake ->y= 300;
snake->color = RED;
snake->compass = COMPRESS_RIGHT;
doublelink_insertback(&list, &(snake->node));
}
for (int i = 0; i < Food_Num; i++)
{
Food_pos[i].x = -1;
Food_pos[i].y = -1;
}
for (int i = 0; i < Master_Num; i++)
{
Master_pos[i].x = -1;
Master_pos[i].y = -1;
}
}
void show(void)
{
cleardevice();
entrylist_foreach(&list,pos)
{
setlinecolor(list_entry(pos, Snake, node)->color);
setfillcolor(list_entry(pos, Snake, node)->color);
fillcircle(list_entry(pos, Snake, node)->x, list_entry(pos, Snake, node)->y, Radius);
}
for (int i = 0; i < Food_Num; i++)
{
setlinecolor(HSVtoRGB(i * 30, 0.6, 1));
setfillcolor(HSVtoRGB(i * 30, 0.6, 1));
fillrectangle(Food_pos[i].x, Food_pos[i].y, Food_pos[i].x+(2* Radius), Food_pos[i].y + (2 * Radius));
}
for (int i = 0; i < Master_Num; i++)
{
setlinecolor(RED);
setfillcolor(BROWN);
POINT pts[] = { {Master_pos[i].x, Master_pos[i].y-Radius}, {Master_pos[i].x- Radius, Master_pos[i].y + Radius}, {Master_pos[i].x + Radius, Master_pos[i].y + Radius} };
fillpolygon(pts, 3);
}
if (gamestatus == -1)
{
settextstyle(WindowHeight/ 20, 0, _T("宋体")); // 设置文字大小、字体
// 设定文字颜色,不同数值,颜色不同
settextcolor(RGB(120, 120, 120));
RECT r = { 0,0,WindowWidth,WindowHeight };
if (gamestatus == -1)
drawtext(_T("游戏失败,按任意键重新开始"), &r, DT_CENTER | DT_VCENTER | DT_SINGLELINE);
else if (gamestatus == 1)
drawtext(_T("游戏胜利,按任意键重新开始"), &r, DT_CENTER | DT_VCENTER | DT_SINGLELINE);
if (!doublelink_isempty(&list))
{
Doublelink_listnode* temp = NULL;
entrylist_foreach_safe(&list, pos, temp)
{
doublelink_removenode(pos);
Snake* snake = list_entry(pos, Snake, node);
if (snake != NULL)
{
free(snake);
snake = NULL;
}
}
temp = NULL;
}
}
Sleep(100);
FlushBatchDraw();
}
void update(void)
{
if (_kbhit())
{
char input = _getch();
switch (input)
{
case KEY_UP:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPREES_DOWN)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_UP;
}
break;
case KEY_DOWN:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_UP)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPREES_DOWN;
}
break;
case KEY_LEFT:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_RIGHT)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_LEFT;
}
break;
case KEY_RIGHT:
if (list_entry_firstnode(pos, Snake, node)->compass != COMPRESS_LEFT)
{
list_entry_firstnode(pos, Snake, node)->compass = COMPRESS_RIGHT;
}
break;
}
if (gamestatus == -1)
{
start_up();
}
}
if (list_entry_firstnode(&list, Snake, node)->x >= WindowWidth|| list_entry_firstnode(&list, Snake, node)->x <= 0\
|| list_entry_firstnode(&list, Snake, node)->y <= 0|| list_entry_firstnode(&list, Snake, node)->y>=WindowHeight\
|| doublelink_nodenum(&list) < 2
)
{
entrylist_foreach(&list, pos)
list_entry(pos, Snake, node)->color = GREEN;
gamestatus = -1;
}
entrylist_foreach((&list)->next, pos)
{
if (list_entry(pos, Snake, node)->x == list_entry_firstnode(&list, Snake, node)->x && list_entry(pos, Snake, node)->y == list_entry_firstnode(&list, Snake, node)->y)
{
gamestatus = -1;
}
}
list_entry_firstnode(&list, Snake, node)->x += dirs[list_entry_firstnode(&list, Snake, node)->compass][0] * Speed*2;
list_entry_firstnode(&list, Snake, node)->y += dirs[list_entry_firstnode(&list, Snake, node)->compass][1] * Speed*2;
entrylist_foreach(&list,pos)
{
if (pos->next != (&list))
{
list_entry(pos->next, Snake, node)->x = list_entry(pos, Snake, node)->x - dirs[list_entry(pos, Snake, node)->compass][0] * Radius * 2;
list_entry(pos->next, Snake, node)->y = list_entry(pos, Snake, node)->y - dirs[list_entry(pos, Snake, node)->compass][1] * Radius * 2;
}
}
for (pos = (&list)->prev; pos != &list; pos = pos->prev)
{
if (pos != (&list)->next)
list_entry(pos, Snake, node)->compass = list_entry(pos->prev, Snake, node)->compass;
}
food_generate();
generate_master();
snake_eatfood();
snake_acrossmaster();
}
void food_generate(void)
{
int count = 0;
int index[Food_Num];
for (int i = 0; i < Food_Num; i++)
{
if ((Food_pos[i].x == -1 && Food_pos[i].y == -1))
{
index[count]=i;
count++;
}
}
while(count)
{
uint16_t x_rand = rand() % (WindowWidth - 2* Radius);
uint16_t y_rand = rand() % (WindowHeight - 2 * Radius);
int pos_legal = 1;
for (int i = 0; i < Food_Num; i++)
{
if ((Food_pos[i].x == x_rand && Food_pos[i].y == y_rand))
{
pos_legal = 0;
break;
}
}
for (int i = 0; i < Master_Num; i++)
{
if (Master_pos[i].x == x_rand && Master_pos[i].y == y_rand)
{
pos_legal = 0;
break;
}
}
if (pos_legal)
{
Food_pos[index[count-1]].x = x_rand;
Food_pos[index[count-1]].y = y_rand;
count--;
}
}
}
void snake_eatfood(void)
{
for (int i = 0; i < Food_Num; i++)
{
if ((list_entry_firstnode(&list, Snake, node)->x) >= Food_pos[i].x- Radius && (list_entry_firstnode(&list, Snake, node)->x) <= Food_pos[i].x + 3 * Radius &&\
(list_entry_firstnode(&list, Snake, node)->y) >= Food_pos[i].y- Radius && (list_entry_firstnode(&list, Snake, node)->y) <= Food_pos[i].y + 3 * Radius \
)
{
Food_pos[i].x = -1;
Food_pos[i].y = -1;
Snake* snake = (Snake*)malloc(sizeof(Snake));
snake->color = GREEN;
snake->compass = list_entry((&list)->prev,Snake,node)->compass;
doublelink_inserttop(&list,&(snake->node));
return;
}
}
}
void generate_master(void)
{
uint8_t count = 0;
int index[Master_Num];
for (int i = 0; i < Master_Num; i++)
{
if (Master_pos[i].x == -1 && Master_pos[i].y == -1)
{
index[count] = i;
count++;
}
}
while (count)
{
uint8_t poslegal=1;
uint16_t x_pos = Radius + rand() % (WindowWidth - 2 * Radius);
uint16_t y_pos = Radius + rand() % (WindowHeight - 2 * Radius);
for (int i = 0; i < Master_Num; i++)
{
if (Master_pos[i].x == x_pos && Master_pos[i].y == y_pos)
{
poslegal = 0;
break;
}
}
for (int i = 0; i < Food_Num; i++)
{
if (Food_pos[i].x == x_pos && Food_pos[i].y == y_pos)
{
poslegal = 0;
break;
}
}
if (poslegal)
{
Master_pos[index[count-1]].x = x_pos;
Master_pos[index[count-1]].y = y_pos;
count--;
}
}
}
void snake_acrossmaster(void)
{
for (int i = 0; i < Master_Num; i++)
{
if ((list_entry_firstnode(&list, Snake, node)->x) >= Master_pos[i].x - Radius && (list_entry_firstnode(&list, Snake, node)->x) <= Master_pos[i].x + Radius \
&& (list_entry_firstnode(&list, Snake, node)->y) >= Master_pos[i].y - Radius && (list_entry_firstnode(&list, Snake, node)->y) <= Master_pos[i].y + Radius
)
{
for (int j = 0; j < 2; j++)
{
Snake* snake = list_entry((&list)->prev,Snake,node);
doublelink_removenode((&list)->prev);
if (snake != NULL)
{
free(snake);
snake = NULL;
}
}
Master_pos[i].x = -1;
Master_pos[i].y = -1;
}
}
}
void doublelink_listinit(Doublelink_listnode* list)
{
list->prev = list;
list->next = list;
}
void doublelink_insertback(Doublelink_listnode* list, Doublelink_listnode* node)
{
node->next = list->next;
list->next->prev = node;
list->next = node;
node->prev = list;
}
void doublelink_inserttop(Doublelink_listnode* list, Doublelink_listnode* node)
{
list->prev->next = node;
node->prev = list->prev;
node->next = list;
list->prev = node;
}
void doublelink_removenode(Doublelink_listnode* node)
{
node->prev->next = node->next;
node->next->prev = node->prev;
node->next = node;
node->prev = node;
}
int doublelink_isempty(Doublelink_listnode* list)
{
return (list->next == list);
}
uint8_t doublelink_nodenum(const Doublelink_listnode* list)
{
uint8_t len = 0;
const Doublelink_listnode* p = list;
while (p->next != list)
{
len++;
p=p->next;
}
return len;
}
排序是编程中经常用到的数据处理方法,比如说我们可能要对实验数据进行分析,对高考成绩进行排名,在嵌入式领域中,常常要对MCU中ADC采集的数据进行排序处理,具有高频出现的特征,所以好的排序方法对于数据处理的准确,提升程序运行效率具有重要的意义。一般我们常用的排序方法有一下几种,插入排序,选择排序,冒泡排序,快速排序等等,其中Visual Studio提供了快速排序的API,我们可以方便调用qsort,但是我们点进去函数定义时可以发现,VS只提供了接口,而没有展示具体实现,下面,我尝试通过我对排序算法的一些理解,模拟一下qsort的实现。

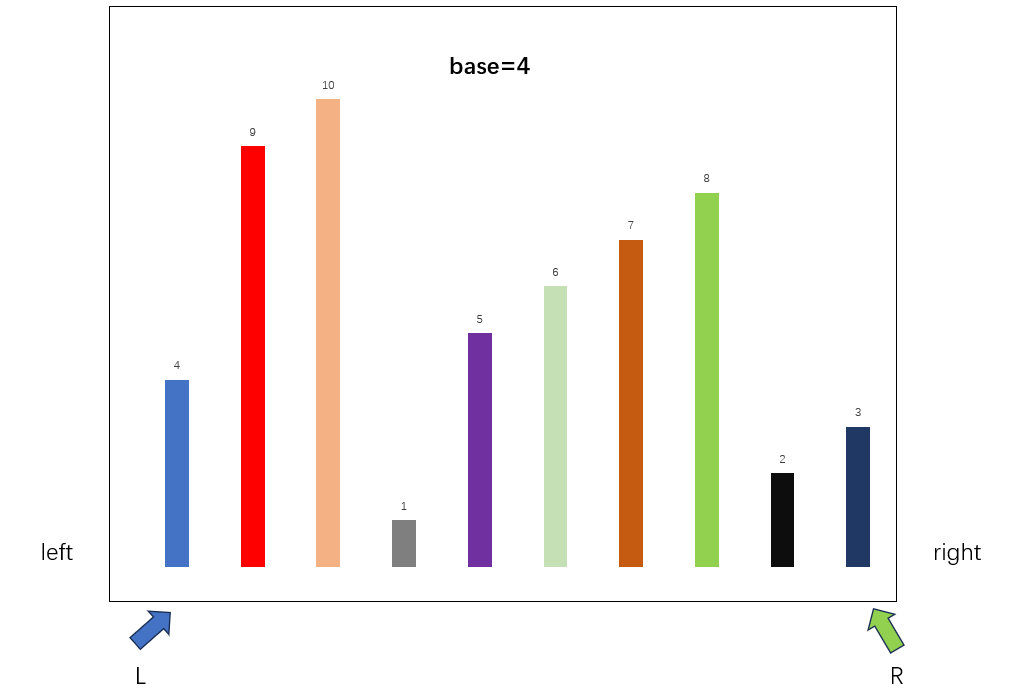
排序目前主要有以下几种算法,插入排序,选择排序,冒泡排序,快速排序算法,其中插入排序,选择排序,冒泡排序算法的时间复杂度为O(n^2),在处理大量数据时效率不高,而快速排序的时间复杂度比较低,为O(log2N),所以我选择通过快速排序算法,模拟Visual Studio IDE中的实现。快速排序采用的是分而治之的思想,每次从数组中取一个元素作为基准值,将小于基准值的元素放左边,大于基准值的元素放右边,通过对左,右区域进行迭代操作,最终实现排序。示意图如下:
 ![51b3f240-6478-44f3-9065-0e0f08c2c334-image.png]
![51b3f240-6478-44f3-9065-0e0f08c2c334-image.png]
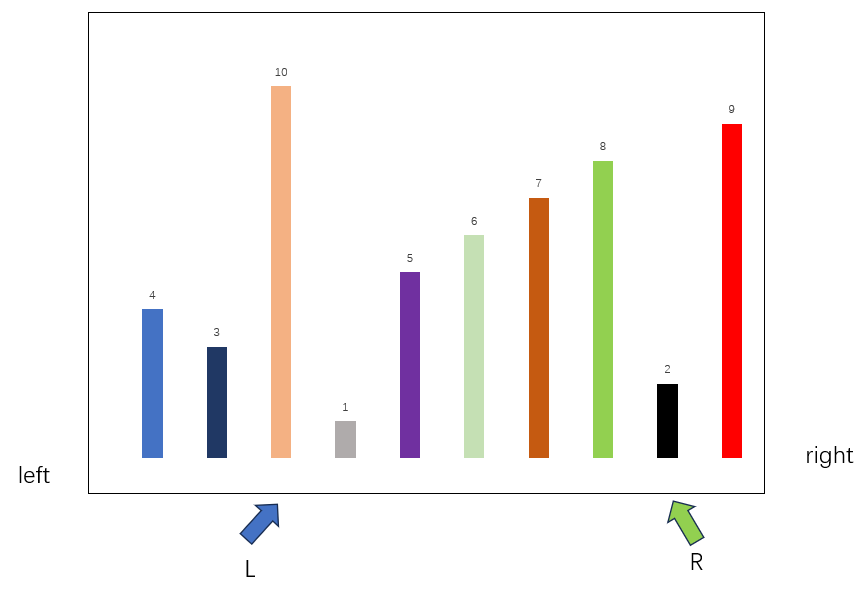
先确定本次排序的数组边界,分别是left,right,随后初始化指针L,R,分别指向本轮迭代的边界,将比较基准设置为数组第一个元素,在本轮迭代中,base=4,随后开始查找数组元素交换,将R向左移动,寻找比base小的数据,将L向右移动,寻找比base大的数据,当两者都找到合适的数据后,互相交换,即可实现排序。
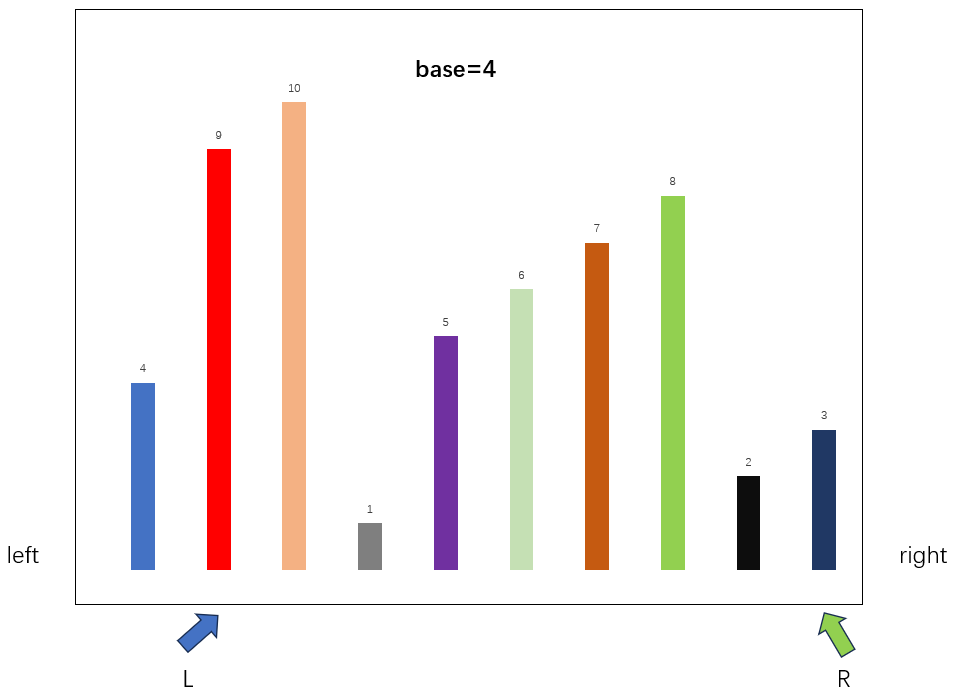
交换
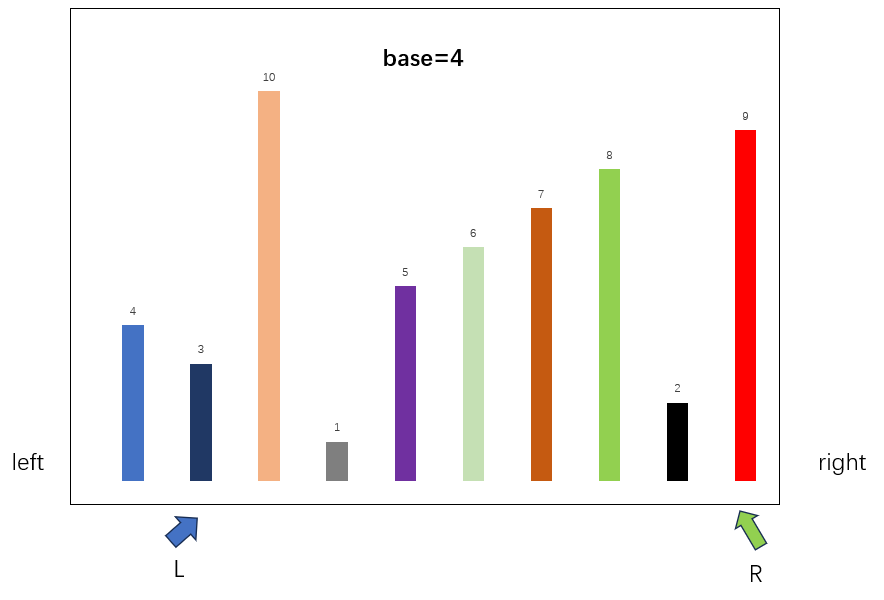
继续查找下一组合适的元素
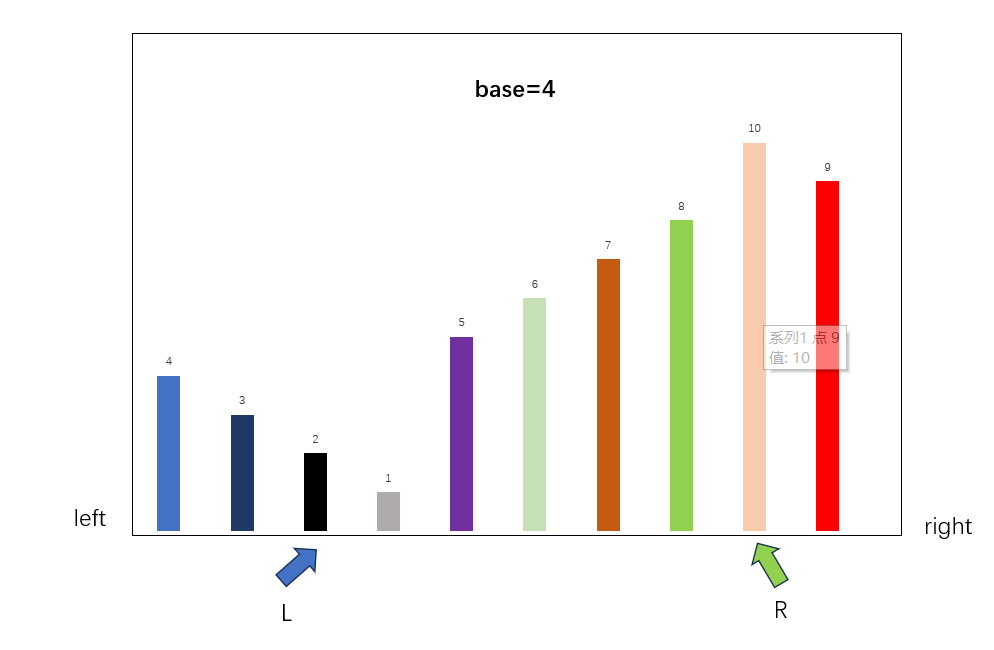
交换
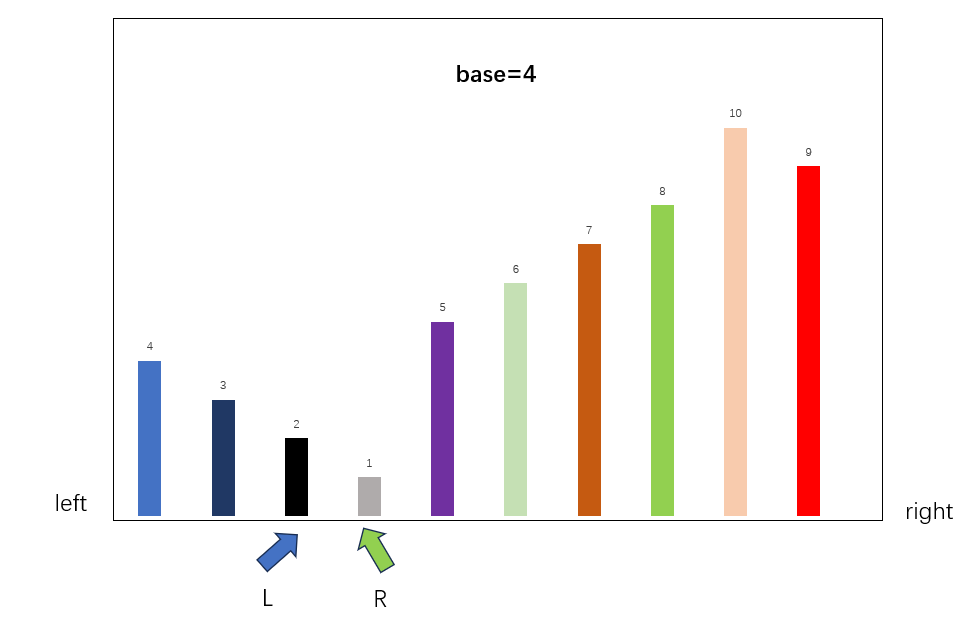
依此类推(注意是要先移动右边的R指针,确定其符合要求再移动左边的指针)
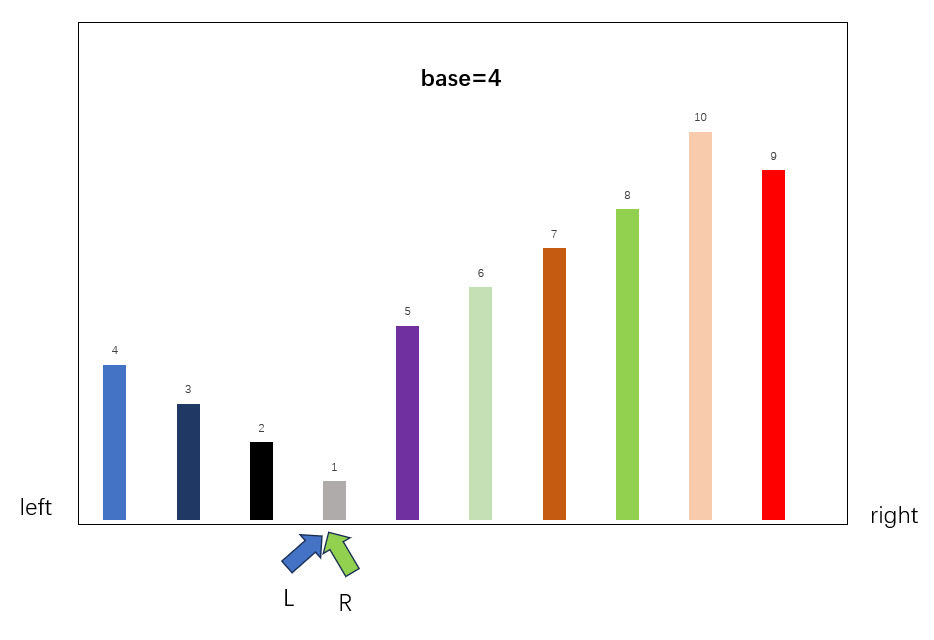
此时右移动L指针,L和R重叠,无法满足交换条件,证明R指针右边的数都比Base大,于是交换Base和R,进行下一轮排序
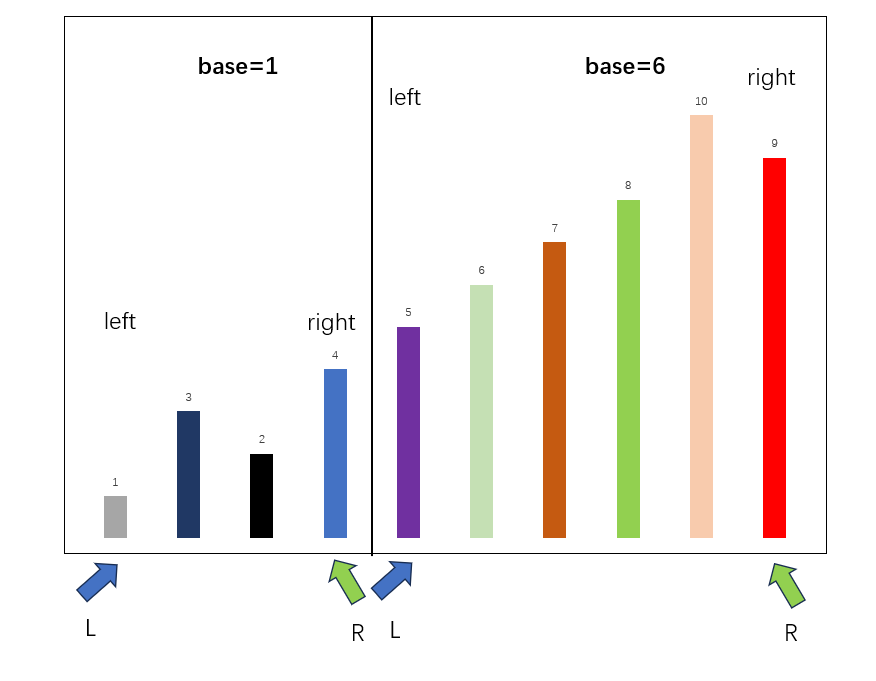
通过不断迭代,我们每次将排序范围缩少一般,所以经过O(log2N)次,我们即可实现排序。
代码具体实现如下
void my_qsort(uint8_t array[], uint8_t left, uint8_t right)
{
int base = array[left];
uint8_t L = left;
uint8_t R = right;
while (L < R)
{
while ((array[R] > base)&&L<R)
{
R--;
}
while ((array[L] <= base)&&L<R)
{
L++;
}
uint8_t temp;
temp = array[R];
array[R] = array[L];
array[L] = temp;
}
uint8_t temp;
temp = array[L];
array[L] = array[left];
array[left] = temp;
if(left<L)
my_qsort( array, left, L-1);
if(R<right)
my_qsort( array, R+1, right);
}
int main()
{
uint8_t array[10] = { 0 };
srand((unsigned)time(NULL));
for (int i = 0; i < 10; i++)
{
array[i] = i+1;
}
for (int i = 0; i < 5; i++) //生成无序随机数
{
uint8_t j = rand() % 10;
uint8_t k = rand() % 10;
uint8_t temp;
temp = array[k];
array[k] = array[j];
array[j] = temp;
}
printf("data:");
for (int i = 0; i < 10; i++)
{
printf("%d ", array[i]);
}
printf("\r\n");
my_qsort(array,0,9); //进行排序
printf("after sort:");
for (int i = 0; i < 10; i++)
{
printf("%d ", array[i]);
}
}
看看运行效果

但是,这个函数形式跟Visual Studio提供了快速排序的API还有较大区别,探索完原理后我们还需要将快排算法,写成Visual Studio提供API的形式。
_ACRTIMP void __cdecl qsort(
Inout_updates_bytes(_NumOfElements * _SizeOfElements) void* _Base,
In size_t _NumOfElements,
In size_t _SizeOfElements,
In _CoreCrtNonSecureSearchSortCompareFunction _CompareFunction
);
首先,我们观察qsort的传参部分,其参数有未定义类型指针Base(指向需要比较元素的地址),_NumOfElements(需要比较的元素数量),_SizeOfElements(元素的字节大小),_CompareFunction(函数指针,确定元素的比较方法)
将我们自己编写的my_qsort和qsort对比即可知道,我们如何改写自己的函数。
观察void my_qsort(uint8_t array[], uint8_t left, uint8_t right),参数指针array(指向需要比较的元素地址),left(需要比较的起始元素下标),right(需要比较元素的终止下标),其实到这里,就比较清晰了,参数array跟base其实是一样的,指代比较元素的内存地址所在,_NumOfElements=right-left,指代需要比较元素的数量,_SizeOfElements指元素字节的大小,由于我们自己写的my_qsort是指定单字节的数字比较,可是在实践中,我们常常会有uint16_t,uint32_t甚至是float的比较需求,所以我们可以看到IDE提供的API还是有很大的灵活性,可以对比各种元素,_CompareFunction指元素的对比规则,是升序还是降序,我们下面可以结合具体代码进行分析。
my_qsort是这样定义基准的:
int base = array[left];
uint8_t L = left;
uint8_t R = right;
将其转换为qsort可以这样写,
uint8_t L = 0;
uint8_t R = numofElement-1;
这样可以同样得到,L和R指针的下标,随后进行比较
while (L < R)
{
while ((array[R] > base)&&L<R)
{
R--;
}
while ((array[L] <= base)&&L<R)
{
L++;
}
uint8_t temp;
temp = array[R];
array[R] = array[L];
array[L] = temp;
}
可以这样改写
while (L < R)
{
while (CompareFunction((unsigned char*)base + (R * sizeofElement), (unsigned char*)base)>0 && L < R) //array[R] > base
{
R--;
}
while (CompareFunction((unsigned char*)base + (L * sizeofElement), (unsigned char*)base) <= 0 && L < R) //array[L] <= base
{
L++;
}
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement)+i;
unsigned char* buf2 = (unsigned char*)base + (R * sizeofElement)+i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
}
从这里可以看到,sizeofElement的作用就发挥出来了,我们自己实现的my_qsort是array[R] > base进行比较,但是我们这里比较只知道起始地址base和字节大小sizeofElement,但是我们知道数据地址和数据类型,我们就可以求得其元素,我们平时的指针操作就是这样的。
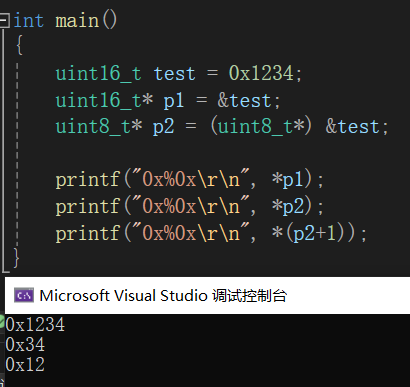
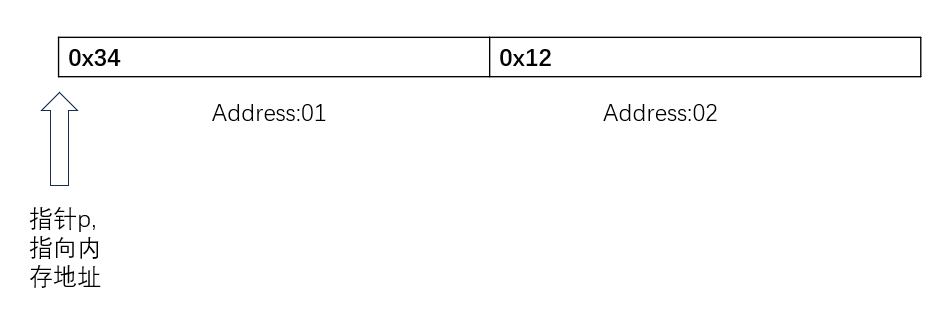
当指针p1指向address:01时,并按照uint16_t进行解释,就是把两个字节的内存数据进行整合分析,所以打印结果是0x1234,当指针p2指address:01时,并按照uint8_t进行解释时,解释的是单字节,所以打印结果是0x34,当p2在内存移动,p2+1时,p2指向address:02地址时,解释为0x12,当然,数据在内存上的分布,跟硬件的大小端有关,这里不展开解释,所以通过(地址+数据类型)的方法,我们可以得到数据大小,并进行比较,而不用像我们的my_qsort函数一样只能固定比较无符号8位数。
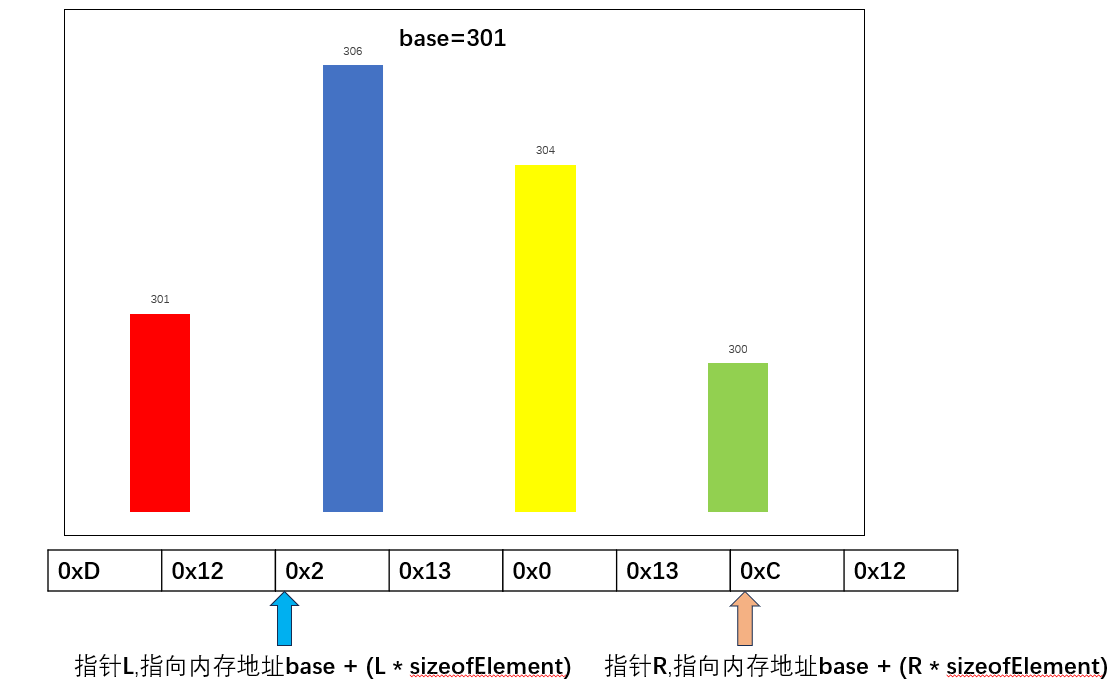
起始地址为base,由于我们的数据是300已经超过了uint8_t的范围,所以只能采用uint16_t,所以,一个数据占用2个字节,即是sizeofElement为2,base=301,R指针指向最后一个数300,其地址为base + (3 * sizeofElement),下标为3,L指针指向306,其地址为base + (1* sizeofElement),跟我们用数组其实是一个寻址原理,然后进行交换
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement)+i;
unsigned char* buf2 = (unsigned char*)base + (R * sizeofElement)+i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
我们交换通过逐字节交换,数量为sizeofElement,最终实现数组元素交换
随后,进行迭代递归,即可完成,下面的函数完整代码
void test_qsort(void* base,uint8_t numofElement,uint8_t sizeofElement, strcmp_fun CompareFunction)
{
uint8_t L = 0;
uint8_t R = numofElement-1;
while (L < R)
{
while (CompareFunction((unsigned char*)base + (R * sizeofElement), (unsigned char*)base)>0 && L < R) //array[R] > base
{
R--;
}
while (CompareFunction((unsigned char*)base + (L * sizeofElement), (unsigned char*)base) <= 0 && L < R) //array[L] <= base
{
L++;
}
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement)+i;
unsigned char* buf2 = (unsigned char*)base + (R * sizeofElement)+i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
}
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement) + i;
unsigned char* buf2 = (unsigned char*)base+i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
if (base < (unsigned char*)base + (L * sizeofElement))
test_qsort(base,L , sizeofElement, CompareFunction);
if ((unsigned char*)base + (R * sizeofElement) < (unsigned char*)base + (numofElement-1) * sizeofElement)
test_qsort((unsigned char*)base+(R+1)* sizeofElement, numofElement-L-1,sizeofElement, CompareFunction);
}
我们在IDE上运行测试一下代码:
typedef int (*strcmp_fun)(const void*,const void*);
int CompareFunction(const void*, const void*);
void test_qsort(void* base, uint8_t numofElement, uint8_t sizeofElement, strcmp_fun CompareFunction);
int main()
{
uint16_t array[10] = { 0 };
srand((unsigned)time(NULL));
for (int i = 0; i < 10; i++)
{
array[i] =rand()%1000;
}
for (int i = 0; i < 5; i++) //生成无序随机数
{
uint8_t j = rand() % 10;
uint8_t k = rand() % 10;
uint8_t temp;
temp = array[k];
array[k] = array[j];
array[j] = temp;
}
printf("data:");
for (int i = 0; i < 10; i++)
{
printf("%d ", array[i]);
}
printf("\r\n");
test_qsort(array, sizeof(array)/sizeof(uint16_t),sizeof(uint16_t), CompareFunction); //进行排序
printf("after sort:");
for (int i = 0; i < 10; i++)
{
printf("%d ", array[i]);
}
}
int CompareFunction(const void* a, const void* b)
{
if (*(uint16_t*)a - *(uint16_t*)b > 0)
return 1;
else
return 0;
}
void test_qsort(void* base, uint8_t numofElement, uint8_t sizeofElement, strcmp_fun CompareFunction)
{
uint8_t L = 0;
uint8_t R = numofElement - 1;
while (L < R)
{
while (CompareFunction((unsigned char*)base + (R * sizeofElement), (unsigned char*)base) > 0 && L < R) //array[R] > base
{
R--;
}
while (CompareFunction((unsigned char*)base + (L * sizeofElement), (unsigned char*)base) <= 0 && L < R) //array[L] <= base
{
L++;
}
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement) + i;
unsigned char* buf2 = (unsigned char*)base + (R * sizeofElement) + i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
}
for (int i = 0; i < sizeofElement; i++)
{
unsigned char temp = 0;
unsigned char* buf1 = (unsigned char*)base + (L * sizeofElement) + i;
unsigned char* buf2 = (unsigned char*)base + i;
temp = *buf1;
*buf1 = *buf2;
*buf2 = temp;
}
if (base < (unsigned char*)base + (L * sizeofElement))
test_qsort(base, L, sizeofElement, CompareFunction);
if ((unsigned char*)base + (R * sizeofElement) < (unsigned char*)base + (numofElement - 1) * sizeofElement)
test_qsort((unsigned char*)base + (R + 1) * sizeofElement, numofElement - L - 1, sizeofElement, CompareFunction);
}

测试成功,目标达成!如果各位大佬有什么更好的建议或者我有什么代码上的错误,欢迎在评论区一起讨论!
最近在看《编程珠玑》提升自己的C语言编程能力,书中的第二章提出了一个有趣的问题。
该问题的描述如下:给定一个最多包含40亿个随机排列的32位整数的顺序文件,找出一个不在文件中的32位整数(在文件中至少缺失一个这样的数--为什么?)。在具有足够内存的情况下,如何解决该问题?如果有几个外部的“临时”文件可用,但是仅有几百字节,又该如何解决问题。
对于为啥文件会确实一个32位的数,这个是显而易见的,我们知道2^32次方是4,294,967,296这个数大于40亿,所以40亿个数是无法完全包含32位整数的全部的。至于,这里有40亿个数,我们怎么找到究竟缺失了哪几个数,这是这个章节考察的重点。我们能不能通过遍历的办法,通过一个基准值然后对比40亿个数,如果能比对成功就证明存在,如果比对不成功,就证明这个数是当前文件所确实的,这个方法当然是可以的,但是在实施是完全不现实的。每比对一个数,就要遍历40亿次(注意,文中指出数据是无序的),所以基本上都要大范围遍历,还要遍历40亿次,这对计算机的性能消耗是巨大的,计算时间也是不可想象的。能不能缩少遍历次数呢,书本提到了位图的方法,通过创建一个大的数组,每个数组的每个位,1代表该数存在,0代表该数不存在,这样,遍历一次即可把位图填满,然后我们再遍历一次位图,看看哪个是0,即可知道究竟是缺失了哪一个数,那这个方法确实可以大大提升计算效率,但是,我们的问题还有一个限制条件,即是内存是有限的,我们很难一次创建一个很大的位图,快速完成遍历。通过理论计算可知,4,294,967,296/8=536,870,912,创建一个完整位图,需要超过500MB的内存,书中最后提出了一个二分搜索的方法。
位图法的原理如下:
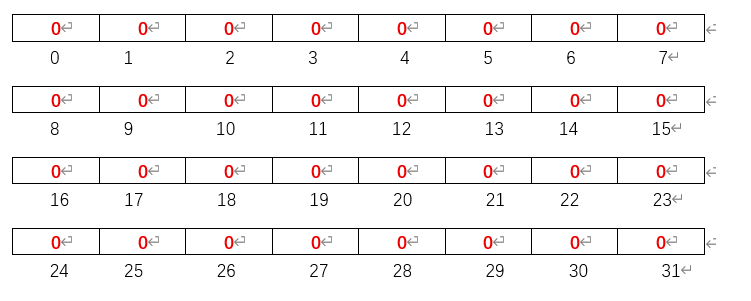
1、首先我们先创建一个位图(本文以32位为例子说明),随后将其整个位图初始化为0:
代码如下,比较简单
首先宏定义,
#define N 31
#define BITWORD 8
uint8_t test_array[N / BITWORD + 1] = { 0 };
随后,我们可以设计位图操作函数,分别是:
void set_bit(uint8_t* array, uint8_t num);//将位图相关位置置1
void set_bit(uint8_t* array, uint8_t num)
{
array[num >> 3] |= (1 << (num & 0x7));
}
void clear_bit(uint8_t* array, uint8_t num);//将位图相关位置置0
void clear_bit(uint8_t* array, uint8_t num)
{
array[num >>3] &= ~(1 << (num & 0x7));
}
其中右移动三位是指,将要填入的数字除以8(毕竟我们是8位数组),我们先看看把该数字安放在哪个数组,随后我们num&0x7,这个意思是指求他的余数,即是num%0x7,我们可以计算出,该数字在数组应该右移多少位,为了程序设计方便,我们可以通过宏定义替换。
#define SHIFT 3
#define Mask 0x7
void set_bit(uint8_t* array, uint8_t num)
{
array[num >> SHIFT] |= (1 << (num & Mask));
}
void clear_bit(uint8_t* array, uint8_t num)
{
array[num >> SHIFT] &= ~(1 << (num & Mask));
}
我建议做这种除法或取模运算时,尽量运用移位的方法,按位与的方法,这样计算效率会高一些。
假设我们将数字22所在的位置值换为1,
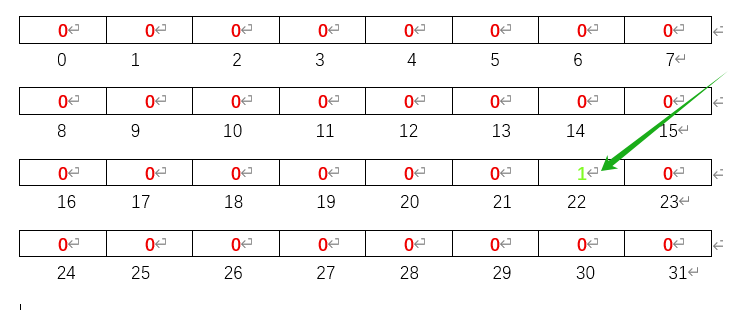
首先,我们通过array[num >> SHIFT],求出我们是将array[2]中的某一位置为1,那究竟是哪一位呢?我们通过num&Mask可以得出是array[2]右移动6位置一,因此我们的置一成功。
接下来,进入到验证部分,
我设计了一个函数:
bool test_bit(uint8_t* array, uint8_t num);//通过判断数字的相应位是否为1,判断该数字是否存在,返回值为布尔量
bool test_bit(uint8_t* array, uint8_t num)
{
return array[num >> SHIFT] & (1 << (num & Mask));
}
当我们输入22时,该函数会判断array[2]的第6位是否为1,进而判断我们是否写入过该数字。下面我们演示一下运行结果:


假设我们改为23,
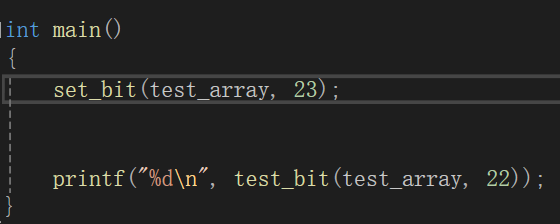

输出符合预期。源代码如下:
#define BITWORD 8
#define SHIFT 3
#define N 32
#define Mask 0x7
void set_bit(uint8_t* array, uint8_t num);
void clear_bit(uint8_t* array, uint8_t num);
bool test_bit(uint8_t* array, uint8_t num);
uint8_t test_array[N / BITWORD + 1] = { 0 };
int main()
{
set_bit(test_array, 22);
printf("%d\n", test_bit(test_array, 22));
}
void set_bit(uint8_t* array, uint8_t num)
{
array[num >> SHIFT] |= (1 << (num & Mask));
}
void clear_bit(uint8_t* array, uint8_t num)
{
array[num >> SHIFT] &= ~(1 << (num & Mask));
}
bool test_bit(uint8_t* array, uint8_t num)
{
return array[num >> SHIFT] & (1 << (num & Mask));
}
我们可以通过位图法,读取文件中的数字,将位图相应位置置一,随后通过我们设计的验证函数,看看该数是否存在,如不存在,就可以输出该数据,但正如之前分析,该方法需要的内存呢非常大。
下面我们介绍一下,该问题的解决方法,二分查找法,为了演示方便,我们假设存在一个数组,里面的数据在0-16之内,即是4位的数据。那么我们应该如何找到4位数据中的,缺失的数字呢?这里简要介绍一下思路,示意图图下
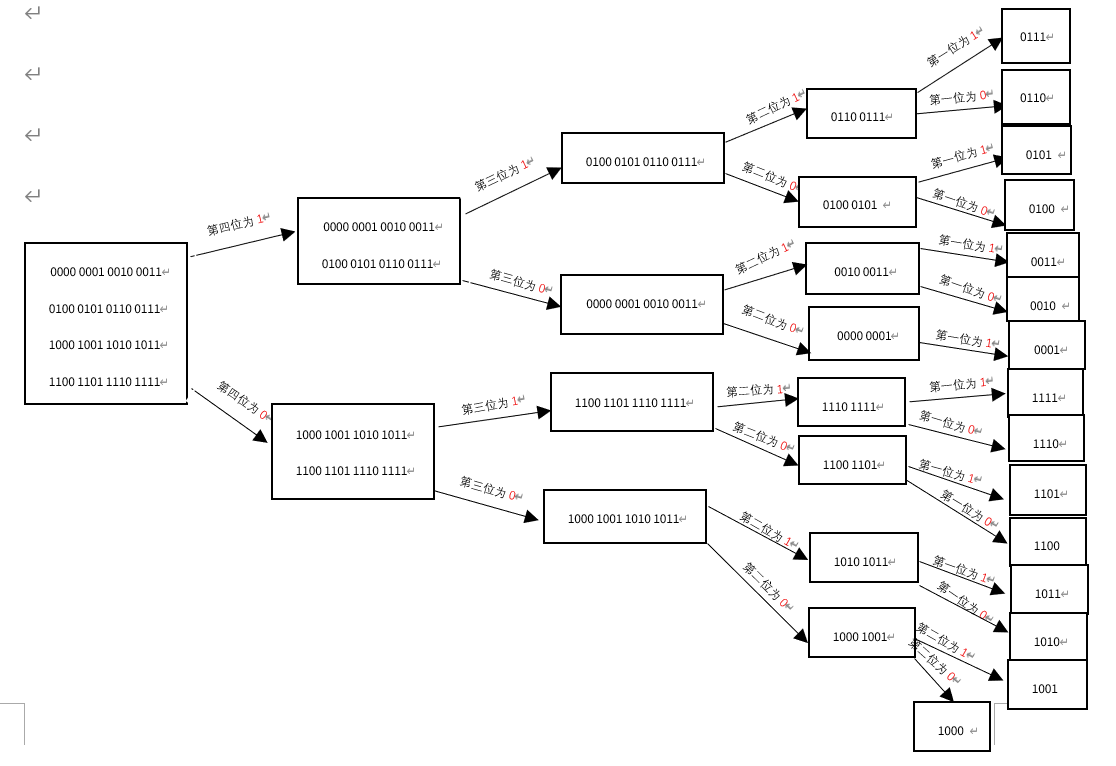
假设我们有16个数,0000,0001,0010,0011,0100,0101,0110,0111,1000,1001,1010,1011,1100,1101,1110,1111,我们发现,这四位数,高位不是1,就是0,通过划分高位0和1,我们可以产生以上的树状图,比如说,第四位为1时,可以分为1000,1001,1010,1011,1100,1101,1110,1111,第四位为0时,可以分为0000,0001,0010,0011,0100,0101,0110,0111,细心观察,我们可以发现,第四位为1时,在0-15的范围内,可以分为0-7,8-15两个区间,此时,我们可以进一步细分,在8-15的区间内,第三位为1时,区间为12-15,第三位为0时,区间为8-11,在0-7区间内,第三位为1时,区间为4-7,第三位为0时,区间为0-3,依次类推,通过这种二分法,可以快速得到各个区间的数字所在区域。同时,我们可以利用原理,快速排查区间中缺少的数字,我们利用递归法,从原始数据开始进行分类,0-15中,假如第四位为1,没能在数组得到数字时,证明,8-15的区间的数字全部缺失,我们可以快速得到数组中缺失的数字,假如第四位为0没能在数组得到数字时,证明0-7的数字全部缺失,当然,有时候,缺失的数字没有那么多,高四位为1和高四位为0都能找到相应的数字,### (需要注意的是,经过上一次的分类,这时候,我们已经分别得到第四位为1和第四位为0的数字分别构成的两个数组,我们需要在此基础进一步细分查找)###,在0-7的区间内,分别查找第3位为1和第3位为0的数字,假如第三位为1的数字没有找到,证明缺失4-7的数字,假如第3位的数字没有找到,证明缺失0-3的数字,假如他们都有,我们可以将搜索到的数字,分别归为4-7和0-3两个数组,进入下一轮搜索,直到搜索到没有相应的数据,进行返回,依次类推,我们从判断第四位为1或零,一直搜索到第一位是1或0,总能把缺失的数据找出来。
我们以0-15的数组中,缺少5和缺少11,10为例
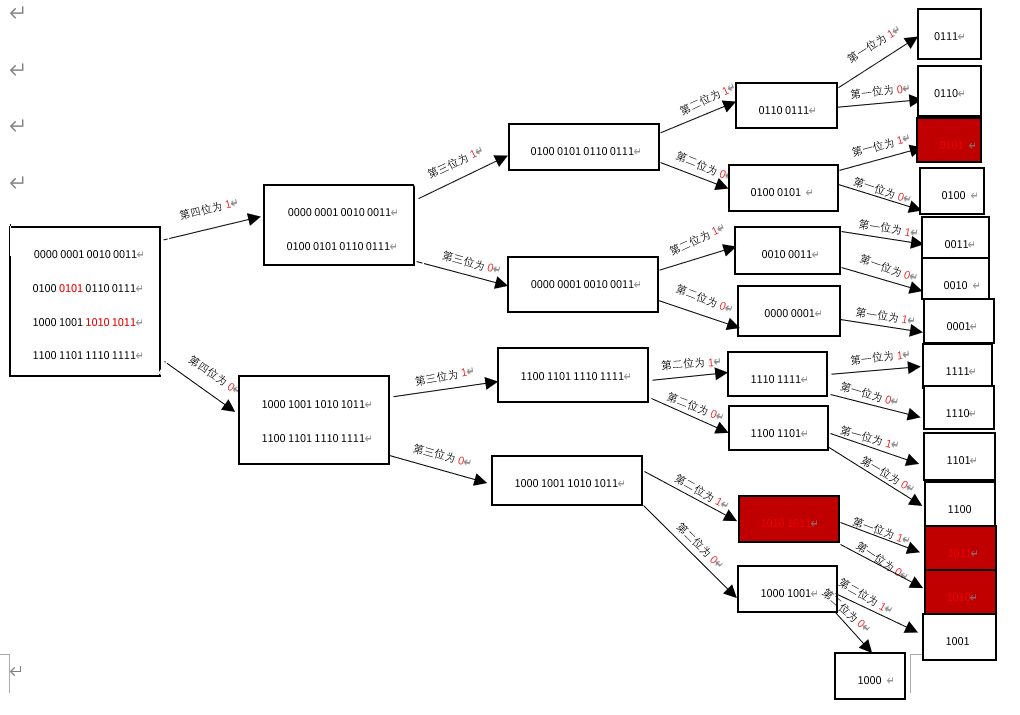
当我们通过二分法,不断细分划分区间时,在{4,5}区间内通过划分第四位为0或1,我们可以找到,我们的数字5是缺失的,通过{8,9,10,11}通过划分第二位为0或1,我们可以找到,10和11是缺失的,一次找出了两个缺失数字,这就是二分法的高明之处。下面,我们演示一下代码运行的结果:
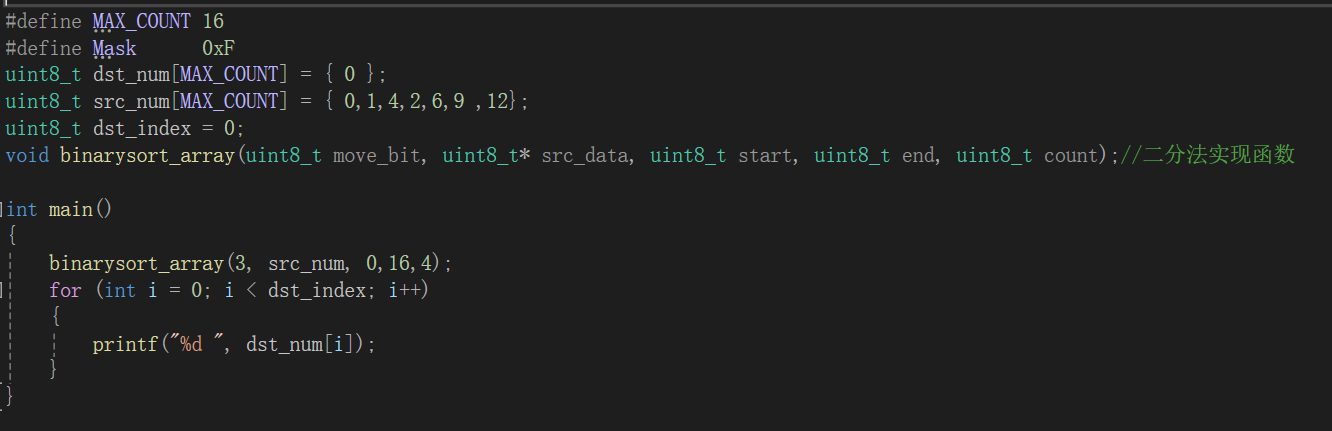
创建数组,源数组src_data有{0,1,4,2,6,9,12}7个数字,我们同时创建一个数组,src_data记录缺失的数字,并打印出来,运行结果如下:

结果运行正确。下面我们贴出实现代码过程:
#define MAX_COUNT 16
#define Mask 0xF
uint8_t dst_data[MAX_COUNT] = { 0 }; //目标数据(缺失的数字)
uint8_t src_data[MAX_COUNT] = { 0,1,4,2,6,9 ,12}; //源数据
uint8_t dst_index = 0;
void binarysort_array(uint8_t move_bit, uint8_t* src_data, uint8_t start, uint8_t end, uint8_t count);//二分法实现函数
int main()
{
binarysort_array(3, src_data, 0,16,4);
for (int i = 0; i < dst_index; i++)
{
printf("%d ", dst_data[i]);
}
}
void binarysort_array(uint8_t move_bit, uint8_t* src_data, uint8_t start,uint8_t end,uint8_t count)
{
uint8_t Bit_zero_array[MAX_COUNT] = { 0 }; //存储Bit位为0的数组
uint8_t Bit_one_array[MAX_COUNT] = { 0 }; //存储Bit位为1的数组
uint8_t Bit_zero_index = 0;
uint8_t Bit_one_index = 0;
for (int i = 0; i < count; i++)
{
if (((src_data[i] >> move_bit) & 0x1) == 1)
{
Bit_one_array[Bit_one_index++] = src_data[i]; //将源数据分为两个区间,此为Bit为1的区间,并用Bit_one_index记录其数量
}
else
{
Bit_zero_array[Bit_zero_index++] = src_data[i]; //将源数据分为两个区间,此为Bit为0的区间,并用Bit_zero_index记录其数量
}
}
if (Bit_one_index == 0) //假如Bit为1的数目等于0,证明区间相应的数字缺失
{
for (int i = (start+end)/2; i < end; i++)
{
dst_data[dst_index++] = i;
}
}
else if (Bit_one_index != 0 && move_bit > 0) //将Bit为0的数组送入下一轮筛选
{
binarysort_array( move_bit-1, Bit_one_array, (start+end)/2,end, Bit_one_index);//不断细分区间
//8-15 (start+end)/2,end
//12-15 //4-7
//14-15 //10-11 //6-7 //2-3
}
if (Bit_zero_index == 0) //假如Bit为0的数目等于0,证明区间相应的数字缺失
{
for (int i = start; i < (start+end)/2; i++)
{
dst_data[dst_index++] = i;
}
}
else if (Bit_zero_index != 0 && move_bit > 0) //将Bit为1的数组送入下一轮筛选
{
binarysort_array(move_bit - 1, Bit_zero_array, start,(start+end)/2, Bit_zero_index); //不断细分区间
//0-7 start,(start+end)/2
//0-4 //8-11
//0-1 //4-5 //8-9 //12-13
}
}
以上就是我关于该问题的一些个人心得,欢迎各位大佬提出建议,不吝赐教!
@sunrisepeak UP主可以看看乐鑫董办那个公众号,它的视频号里面有乐鑫科技参加字节火山引擎发布会的视频,算是对AI+潮玩理解比较深的,可能这个是一个切入点,以后这方面的延伸应该很多。
@sunrisepeak 在 在STM32启动文件中加入版本号 中说:
@sky-littlestar OTA固件下载是和实际app分开的, OTA固件本身应该只能通过手动升级吧 还是说也能OTA呢 或者 一般app和ota程序都统一视为 app 方式的进行升级更新
OTA程序放在APP里面,也是可以进行更新的
最近嵌入式+AI这个领域比较火,UP对这个领域感兴趣吗?有研究过这方面吗?
@sunrisepeak 但是如果将版本号,直接放在中断向量表的好处是,操作比较简单,而且是在启动文件里,一开机上电,就可以立刻知道版本号,我看过一些案例,由于电路设计的时候运行不稳定,如果开机要初始化太多外设,就很容易死机重启,这时候直接放版本好在这里,对于功耗的需求,也没有那么高
实际使用中一般会在ROM里面专门划分一个区域存放固件参数,包括版本号,配置特性等等,而且会对参数做一个备份,毕竟Flash的擦除,更新不是原子操作,如果在FLASH的刚好擦除,更新版本号的过程中断电了,那就没有办法知道版本号了,影响到校验工作,设备就变成砖头了,目前比较主流的OTA方法是,一个BOOTLOADER,两个或着3个APP区域,bootloader用于校验或者引导,1个APP区代表当前的运行域,1个APP区代表旧的APP,算是备份,用于安全作用或者回退,还有1个APP区域用于下载新的APP固件,在受到OTA升级指令后,会引导新的APP下载到APP新区域,然后,重启机器,bootloader会检查是否有新的版本号APP区域,如果有,会直接将新的APP区域覆写到APP运行域,覆写完成后,bootloader跳转到APP运行域,然后就运行新的APP程序了
我们平时在单片机上编写程序,生成固件的时候,一般都会在固件里面添加版本号信息,方便下一次修改或者进行OTA升级。目前,写入固件版本号信息主要有以下两种方法,一种是通过使用关键字attribute,在编译阶段,把固件版本号固定到flash中(注意:attribute是GNU编译器特有的,我在MDK上能实现,但是在微软的Visual stido发现是实现不了的)。另外一种方法是,通过在开机后,读写flash,对flash解锁,随后写入相关信息,然后再给flash上锁,完成一次固件信息的固化。但是,今天我想要介绍第三种方法,即是通过在STM32启动文件中,直接在保留的字节里加入版本号信息,方便又快捷,下面我们详细来对比以下四种方法的优劣之处。
首先,第一种方法,通过关键字attribute在固件中添加相关信息,其具体语法如下,const uint32_t fw_version __attribute((at(address))=XX;
由于信息是固化在flash里面,其属于非易失性的ROM,而且我们在程序运行过程中也不会去修改固件标记,所以加上const关键字,fw_version代表你要写进去的版本号,address代表你要写入的地址位置,例如,我要在0x08000010处写入我的版本号位1.0.0,我们可以这样写,const uint32_t fw_version __attribute((at(address))=100;下面我们可以看看运行效果, 我的芯片是STM32-F103ZET6,首先,先看看不烧录固件地址的程序运行状况,方便对比。


此时程序运行正常,在右侧的flash中,0x08000000是栈顶指针,0x08000004是PC指针,后面依次是启动文件中规定的中断地址,程序没有问题。flash中的中断地址比函数的地址+1是由于Thumb-2指令集要求跳转地址的最低有效位(LSB)必须是1,所以其记录的地址会加1,程序烧录后,能正常运行。此时,我们尝试使用attribute将相关固件信息,固定在指定地址,我们再打开map表和查看flash上的信息,发现上面的地址信息会乱掉,程序启动后,进入死机状态。

观察FLASH上的数据我们可以发现,0x08000010处成功地写入100,证明我们的写入是有效的,但是,我们细心观察可以发现,在0x8000000和0x08000000处已经不是程序PC指针跳转地址和栈顶地址了,程序无法正常启动,观察左侧LR寄存器,0xFFFFFFF9进入硬件错误,证明通过这种写法去写入固件信息是不可行的。我们再看看map表,固件信息前面都是一些C的库函数,而中断信息已经不见了,反而放在0x08001000的后面,
由于,在地址的前面处加入,会导致flash上烧录的信息错乱,所以我们只能尝试在flash的后面加入,以致于其不影响其他函数烧录到相应的flash地址,我尝试在0x0800FFF0处写入,
const uint32_t fw_version __attribute((at(0x0800FFF0)))=100; 此时,程序能正常运行,也成功在固定地址写入,但是我们观察flash可以发现,写入地址前面的数据也受到影响,单片机上的flash在没写入的状态下,一律初始化为FF,现在,都是00,证明使用这个方法,会导致一个扇区的浪费,所以使用attribute+固定地址并不是一个好的方法。

我们还可以使用另外一种方法写入固件信息,STM32单片机内部是norflash,所以我们可以按字节去寻址写入,非常方便,而不必像NANDFLASH那样去,先进行页擦除,再进行页写入,整个过程比较耗费时间,对系统的实时性有一定的影响。但是由于FLASH具有只能从1写到0的特性,而不能从1写道0,所以,我们写入相应的区域地址时,依然需要校验当前写入区域是否全为0XFF,如果不是全为0XFF,我们依然需要进行扇区擦除,为之后的写入作准备。下面我们进行简单的演示。
首先,先进行Flash上面的数据读取,函数实现如下:

将两个8位数据凑成一个半字的数据,然后写入,其中STM32_PAGE_SIZE宏定义为2048,这个根据芯片的FLASH每一页大小确定




最后发现,FLASH上成功写入数据。

但是使用该办法,无法利用中断区域没有利用的保留字空间,因为程序运行中,会发生各种中断,如果对中断向量表的区域进行擦写,这是不被允许的,所以虽然使用Flash擦写的方式能够精确到每一个地址,不用造成扇区浪费,但还是无法利用中断向量表的保留字空间,而且,此办法,需要编写相应的FLASH擦写程序,也比较费时费力。
于是,我们可以利用分散加载技术,通过将我们定义的段固定到指定的地址,指定其大小,随后我们再往段里面写入的相应的数据,我们即可在编译的时候,将数据擦写到固定的位置。这样的方法,比通过程序进行写Flash要简单,也是通过编译时的烧录算法,直接将变量烧写到指定位置,但是由于单片机一开始就已经指定了头部存放的中断变量,跳转地址等信息,没办法在这些空间加入新的段,所以也只能在没有使用过的空间指定地址,但是分段后有一个好处,就是分段后再使用attribute与直接使用attribute相比,可以精准地在相关地址写入变量信息,而不必对扇区的其他位置造成影响,节约了空间。我们可以看一看运行效果。


但是以上三种方法依然无法实现我们使用启动文件保留字空间的办法,最后,我请教了硬汉嵌入式论坛的大佬,通过总结发现,中断向量表中,其位置存储的就是函数的执行地址,也即是函数名直接被翻译为地址存储了,那我们不用通过翻译,直接把数字写进去,可不可以呢,我们实践了一下,最后惊喜的发现,是可以的。下面我们可以看一下效果。

踏破铁鞋无觅处,得来全不费功夫。虽然大费周章,最后发现仅需要通过在启动文件直接添加相关变量即可,但是这次的研究过程也带来不少收获,希望各位大佬共同研究。
@sunrisepeak 在 如何使用ImGui中的DrawList制动一个动画控件? - Loading动画控件 中说:
根据每一帧到lambda表达式的插值动画数据实现动态的更新滑动块的坐标
请问这个具体的计算过程的怎样的呢?有相关的参考资料吗?
请问在滑块移动的过程中是先把滑块,通过父对象渲染的方式,把父对象还原,然后再通过计算滑块的坐标,重新在父对象上面绘制滑块来实现的吗?(还原父对象->计算滑块坐标->重新绘制滑块形成新的一帧),是这种方法吗?
最近在研究rt_thread的源码,发现struct task_struct结构体没有找到定义,但是一些函数却以此作为类型传参数,task_struct的定义应该怎么找,或者说,这是一种什么用法吗?
