@wlly-lzh 智能指针是简化了步骤,不需要你为所有的资源都写一个类包裹,提供了一个通用的托管容器,且还和指针兼容。并且顺手还解决了套壳的问题,RAII对象如果本身也申请在动态空间,套智能指针就不用再写一个套壳类再生成对象托管了。用到对象生命周期去托管的都是RAII,比如各种作用域锁,线程锁这些,都可以用这个思想自动托管
dustchens
@dustchens
-
从小白的视角探究 vector 第一章补充内容 -
从小白的视角探究 vector 第2章@dustchens 在 从小白的视角探究 vector 第2章 中说:
Vector& operator=(const Vector &other) {
// 注意
if(this != &other) {
this->~Vector();
mSize_e = other.mSize_e;
mCapacity = other.mCapacity;
mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity));
for (int i = 0; i < mSize_e; i++) {
mDataPtr_e[i] = other.mDataPtr_e[i];
}
}
return *this;
}这一章节,需要大家思考这段内容,是否正确,为什么没有加上noexcept,noexcept为什么如此重要,需要后续单开一个章节去讲解
-
从小白的视角探究 vector 第2章 -
从小白的视角探究 vector 第2章2 改进 vector,实现 Big5
这部分内容我们依旧使用sunrisepeak大佬的代码演示,但在后半段,我们将会深入一些内容
2.1 vector需要什么?
经过第一章的描述,我们现在应该思考vector需要什么,由此我们才能得知vector需要实现什么
整块空间类比函数栈,它由空间适配器 Allocator提供,申请一整块内存表现的像数组vector需要一个size,标定数组的边界额外的空间vector是一个动态的数组,它标志着vector的空间可以调整大小,因此需要一个容量capacity
- 额外的空间,并不是再申请一块内存,而是在
整块内存内部,需要区分哪些已经使用,哪些未使用且将来可以使用,一旦突破这个界限,就需要再申请一大块内存进行扩容
经过以上总结,再回看第一章节的内容,可以明显发现一点,只有一个size,这个size既标定了已经使用的数量,又标定了vector能容纳的最大元素数量。这显然是不合理的,即便我们需要把这块空间内都初始化出对象,但依然缺少一个逻辑上能区分已使用量和未使用量的内容。
2.2 添加容量
代码方面我尽量复用之前的,大体讲解可以参照对应的视频讲解,后续讲解我只会说明一些我认为初学者容易不理解的地方
template <typename T, typename Alloc = DefaultAllocator> class Vector { public: // 此处添加mCapacity_e的初始化 Vector() : mSize_e { 0 }, mCapacity_e { 0 }, mDataPtr_e { nullptr } { } Vector(int size) : mSize_e { 0 }, mCapacity_e { size } { // 1. 注意点1 mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity_e)); // 2. 注意点2 for (int i = 0; i < mCapacity_e; i++, mSize_e++) { new (mDataPtr_e + i) T(); } } ~Vector() { if (mSize_e) { // 3. 注意点3 for (int i = 0; i < mSize_e; i++) { (mDataPtr_e + i)->~T(); } Alloc::deallocate(mDataPtr_e, mCapacity_e * sizeof(T)); } } private: int mSize_e; int mCapacity_e; T * mDataPtr_e; };可以看到,大框架基本不变,但是添加了容量后,依旧需要注意语句变化带来的含义
申请空间以容量为标定初始化一个元素mSize_e就需要增长一个元素析构以mSize_e为边界
- 再次对比到函数空间,此时我们就可以理解为什么需要用到
new (mDataPtr_e + i) T();这样的技巧
- 在函数中初始化对象,我们可以直接写下
T aaa,不用我们自己管理这个对象在函数空间内部的哪个地方 - 在vector中,没有这种机制,让对象挨个排列在内部空间中,因此,我们需要手动告诉程序,我们需要在
new(地址) 这个位置,初始化 T() 对象。正是这个不同之处,需要我们使用到placement new,也就是定位。如果有自动的机制,我们甚至可以直接和在函数内部初始化对象一样,丝毫不用关心在函数空间的哪里有这个对象!
如何销毁内容?
- 类比到函数栈中,我们已知函数在退出时会自动调用对象的析构函数,因此我们希望vector也在它自身析构时,显式调用已构建对象的析构函数
- 之所以不需要类似placement new这样的操作,是因为在创建时,需要强制确定内存位置,但是销毁时,我们已经知道了哪些内容已经存在,可以显式直接调用。
capacity的作用
capacity的加入,在目前还看不出区别,这是因为这几个构造函数都是直接让size和capacity相等,但是后续一旦需要再添加元素,产生扩容,那么就会体现出区别。
引入capacity后,我们就需要在脑海中将整块内存划分为不同的区域已构建对象的内存[data, size)这部分内容上已经有了对象,可以看到析构也是以此为界限未构建对象的内存[size, capacity)这部分没有任何内容,构建新内容必须使用placement new这样的技术- 需要再次强调placement new技术,只有在
裸内存上才能使用,也就是如果已经在一个地方用此技术初始化了一个对象,那么再次使用placement new在同一位置创建一个新内容是不允许的!除非先调用析构函数,将对象销毁,变为裸内存的状态才能继续使用。这部分对于新手来说直接理解依旧是非常抽象的,并且这个行为是未定义行为,也就是编译器不会给你强制警告!
类比到函数中,那就是无法第二次调用对象的构造函数进行初始化!因为构造就已经开启了生命周期,再次使用会产生一些列问题,比如内存泄漏,多次析构等等。graph TD subgraph 正确方式 A[已有元素位置: 活对象 T] --> B[调用赋值运算符 *p = val] B --> C[对象值更新,无泄漏 ✅] end subgraph 错误方式 A --> D[❌ 直接 placement new 覆盖] D --> E[旧对象未析构,资源泄漏<br/>或二次析构风险(未定义行为)] endgraph TD subgraph 正确方式 S[栈上对象 T x 已构造] --> T[使用赋值 x = val] T --> U[对象值更新 ✅] end subgraph 错误方式 S --> V[❌ 尝试第二次调用构造函数] V --> W[编译错误:不能直接调用构造函数<br/>或 显式析构后 placement new<br/>导致作用域结束时二次析构] end - 接上一条,那么在某一位置已有对象的情况下,除了调用析构函数将对象销毁,变成裸内存,另外的方法就是调用赋值运算符,以更新内容,包括拷贝赋值和移动赋值。这也和我们在函数内使用 = 进行赋值和更新是同一个道理。
flowchart LR subgraph stack_frame[函数栈帧] V[vector对象\n data / size / capacity] end subgraph heap_buffer[堆上的连续存储] E1[元素0] E2[元素1] S1[空槽位] end V --> E1 V --> E2 V --> S1data data+size data+capacity ↓ ↓ ↓ ┌─────────────────────────┬─────────────────────────┐ │ 已构造对象区 │ 未构造预留区 │ └─────────────────────────┴─────────────────────────┘区域 地址范围 对象状态 可执行操作 已构造对象区 [data, data+size)存在活对象 • 改变内容:用拷贝/移动赋值<br>• 若必须整体替换:先析构,再 placement new(一般不推荐) 未构造预留区 [data+size, data+capacity)原始内存(无对象) • 创建对象:必须通过 placement new 构造<br>• 无“修改”一说,因为没有对象可以修改 这里也可以看出我们类比函数栈的好处,那就是不必拘泥于抽象的、高深的内容,不用一开始就去理解STL标准库的思想
毕竟这是该领域顶级专家的成果,想要短时间内容入门是非常困难的。
但是一旦我们将它和我们日常使用的内容相连,我们就可以通过共性去理解其原理,通过不同之处的探究,带着问题探究其深意2.3 全部构造函数
此处不会详细讲解3/5/0法则,只需要知道如果我们显式定义了析构函数、拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符,其中的任意一项,就需要把这几项全部定义出来(或者删除掉)
简而言之,如果有任意一项资源需要我们手动管理,这几个函数就必须认真对待。因为有手动管理,才需要定义这些内容,而这些内容一旦定义任意一项,移动相关的内容就不会由编译器自动生成,其余的哪怕生成,也是有问题的!1 构造函数的类型
此处简单讲解一下不同类型构造函数的作用和区别,以及一些隐式的条件
默认构造函数 不需要参数就能调用,用于 ClassT t 或 ClassT t{} 这样声明一个对象,没有参数
同时这个函数还有一系列的规则,包括自动生成、被抑制生成等普通构造函数 需要提供参数才能调用 用于 ClassT t(10) 这样的调用
之所以区分,是因为默认构造函数有一系列特殊规则复制构造函数 深拷贝 用于ClassT t_copy(other)这样的形式 对于有手动管理资源的类,不能使用编译器提供的复制构造,必须自己实现深拷贝,否则只会拷贝指针这样的门牌号,指向同一块内存,产生双重释放的问题移动构造函数 窃取资源 用于ClassT t_copy(std::move(other))这样的形式 将资源从别的对象转移到自身,并且需要切断别的对象对于资源的所有权
- 注:不需要参数
不代表没有参数,因为还涉及到默认值等问题。且以上调用形式可能存在部分问题,需要后续研究。这里研究的重点还是这几个内容如何实现 - 注2:std::move 只是代表将对象转换为右值引用的形式,让我们能够调用移动构造函数,但并没有字面意义上的移动功能
1 默认构造函数
在上文中,
Vector() : mSize_e { 0 }, mCapacity_e { 0 }, mDataPtr_e { nullptr } { }就是一个默认构造函数,但是这个函数被我们显式声明了,因为声明了一般的构造函数后,编译器是不会再生成默认构造函数的,除非我们自己再写出来那这样的函数还是默认构造函数吗?
// 注意此处的参数 Vector(int size = 0) : mSize_e { 0 }, mCapacity_e { size } { mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity_e)); for (int i = 0; i < mCapacity_e; i++, mSize_e++) { new (mDataPtr_e + i) T(); } }- 这依然是一个默认构造函数
- 依旧是前文所讲内容,size有一个
默认值,无需参数就能调用,符合规则 - 默认值 需要以后额外补充,大家也可以自行查找相关资料了解
- 同时这个默认构造函数也可以提供参数调用,但这个问题暂时无法深入
2 普通构造函数
此处划分这两个构造函数的方式可能有问题,希望大家可以指出
Vector(int size) : mSize_e { 0 }, mCapacity_e { size }完整代码参照上文中出现的
- 这里的size决定了我们调用的时候必须给出参数才能匹配到该函数,比如用{} 初始的形式,Vector v1{10}; 10代表了初始的容量,以及将这10个空位都初始化上对应的对象
: mSize_e { 0 }使用了C++11提供的初始化器,可以方便地将成员进行初始化,避免遗漏等问题。需要注意的是,初始化的顺序并不由我们写的顺序决定,不考虑继承等情况下,由成员在声明时的顺序决定
3 复制构造函数
为什么需要深拷贝?-
指针 这是一切问题的根源,编译器生成的复制构造,只会去
复制指针的值,这一段同样对应第一章补充内容,正如函数作用域不会管理指针背后的资源,默认生成的拷贝构造也不会去考虑远在天边的内存。 -
内存复制 拷贝的主要意义是对资源的拷贝,简单指针复制是无效的,必须手动提供对资源内存的复制,我们希望得到的是另一块独立的内存资源,而不是当前资源的影子。
由此,我们的目标也就很明确了,申请一块大小相同的内容,并在其上一一复制对象
Vector(const Vector& other) : mSize_e {0}, mCapacity { other.mCapacity } { mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity)); for (int i = 0; i < other.mSize_e; i++, mSize_e++) { new (mDataPtr_e + i) T(other.mDataPtr_e[i]); } }- 接收参数
const Vector&复制复制,首先就是要有另一个对象,因此采用引用的方式,同时不会修改也不允许修改另一个对象的内容,因此使用const修饰 - size capacity 可以看出,这二者是有区别的,再次反映出了前文的内容。整体容量和已构造元素是要区分开的
- placement new
new (mDataPtr_e + i) T(other.mDataPtr_e[i]);需要注意,我们依旧是在裸内存上进行构造,因此仍然需要使用定位new技术
4 移动构造函数
快!Vector(Vector &&other) : mSize_e { other.mSize_e }, mCapacity { other.mCapacity }, mDataPtr_e {other.mDataPtr_e} noexcept { // reset other.mSize_e = 0; other.mCapacity = 0; other.mDataPtr_e = nullptr; }-
接收参数
Vector &&other移动也是要有另一个对象,因此采用右值引用的方式,同时必须修改另一个对象的内容,所以无需const修饰 -
浅拷贝 可以看到移动的本质是浅拷贝,但是之前在复制构造时说不能使用浅拷贝,但是此处又使用了浅拷贝,这是为什么?
// reset other.mSize_e = 0; other.mCapacity = 0; other.mDataPtr_e = nullptr;原因在于,我们 “抛弃” 了拿来移动的那个对象,更准确地说,我们宣布另一个对象不再持有资源了。而之前的复制构造,需要两个对象都有资源,这才是关键区别
-
快 快是最关键的好处,因为只复制几个指针和大小容量等内容,是非常迅速的,但是代价就是另一个vector对象失去了资源
关于右值引用请大家自行查阅相关内容。其实就是为了区别调用的函数,调用移动必须要用这种方式。其他方式依旧可以完成这种内部资源转移,但是为了语义上的区分,这样做是最好的
2.4 特殊运算符 =
注意,此处的主体是运算符,而不是构造函数
- 既然是运算符,区别于构造函数,那就意味着vector对象已经经历过调用构造函数的阶段,也就是初始化成功后,才能调用运算符
- 既然已经初始化过了,说明对象内部是有内容的
- 运算符可以出现自赋值的情况 比如
vec1 = vec1
以上的注意点,构成了我们接下来两个特殊运算符的要点
运算符类型
复制赋值运算符类似赋值构造函数移动赋值运算符类似移动构造函数
- 调用方式都相同,使用
=调用,但是同样,需要用不同的方式去匹配不同的运算符 重写operator=()其中最重要的就是()内参数的选择- 需要有
返回值
1 复制赋值运算符
接下来,我们需要根据代码,来分析上文提到的特殊要点
// 1 Vector& operator=(const Vector &other) { // 2 this->~Vector(); mSize_e = other.mSize_e; mCapacity = other.mCapacity; mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity)); for (int i = 0; i < mSize_e; i++) { mDataPtr_e[i] = other.mDataPtr_e[i]; } // 3 return *this; }可以看出,复制赋值运算符,基本沿袭了赋值构造的思路,但是多了释放自身内容和返回的步骤
- 返回值是vector&
- 既然已经初始化过,有内容,就必须先释放掉vector对象本身的内容,因此调用了vector本身的析构函数
- 对this指针,解引用,获得vector对象,匹配上引用返回
- this指针内容需要大家自行查阅
以上的代码符合了需要释放自身旧内容、返回对象。但是依旧是有问题的,可以看出漏掉了最关键的自赋值的问题
倘若出现
vec1 = vec1这样的代码,那么调用之后,在this->~Vector(); 就把自身内容全部释放了,也就是说 vec1 现在变成了一个空对象,所持有的资源消失,这显然不是我们希望看到的如何做呢? 非常简单,也就是如果判断传进来的对象是自身,那就直接返回,否则就执行销毁自身内容并复制的步骤
Vector& operator=(const Vector &other) { // 注意 if(this != &other) { this->~Vector(); mSize_e = other.mSize_e; mCapacity = other.mCapacity; mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mCapacity)); for (int i = 0; i < mSize_e; i++) { mDataPtr_e[i] = other.mDataPtr_e[i]; } } return *this; }- this != &other this是指向对象本身的指针,而对对象使用 &,取得了地址,也就相当于this,因此此处是地址的比较
- 之所以比较地址,而不是比较对象是否相等,是因为这样最简单,而且比较对象,是需要重写比较相关的运算符才可以进行的
2 移动赋值运算符
Vector& operator=(Vector &&other) noexcept { // 注意 if(this != &other) { this->~Vector(); mSize_e = other.mSize_e; mCapacity = other.mCapacity; mDataPtr_e = other.mDataPtr_e; other.mSize_e = 0; other.mCapacity = 0; other.mDataPtr_e = nullptr; } return *this; }- 可以看出,移动赋值运算符也是类似的结构
2.5 总结
这段将简单总结一下第二章的内容
- 首先我们模仿了函数的效果,但是
手动进行了内存管理,并且手动控制了在这块内存上对象的生命周期 - 解耦了已有元素数量(size)和容量(capacity),这要求我们在构造函数和析构函数以及特殊运算符中,申请空间需要以capacity为大小,控制对象生命周期,需要以size为大小
- 构造函数和特殊运算符的规则,使得我们必须手动实现资源的管理,实现由编译器自动生成的内容无法实现的功能
但是,显然这部分内容是非常
浅显的,大部分的讲解都会提到这些内容,也不过是用几个新技术,在堆内存上模拟了一个数组的功能,并且我们大部分的接口还没有实现。如何再深入进去呢?如何理解标准库的一些思想呢?我们要学习vector,不仅是要学习代码怎么写,怎么实现,更要学习它的思想,需要在代码中抽丝剥茧,提炼出能体现某些原则的东西。
关键!!!!
可以注意到,以上的部分函数,添加了一个叫noexcept的东西
它声明了,该函数不会抛出异常- 异常是我们串联起后续内容,拆解stl思想的一个重要切入点
- 没有异常,我们是难以理解为什么vector的代码如此复杂,复杂的同时还有一系列的原则,仿佛数据库一样
3 noexcept 引发的血案
// TODO
感谢
- 本文代码的核心框架来自 bilibili LH_Mouse大佬的视频。
- 同时也参考了 sunrisepeak 大佬的代码和视频: BV1K1421z7kt。且本文大部分讲解代码直接用的对应的教学文档代码。
-
从小白的视角探究 vector 第一章补充内容1-补充内容
1 对象到底在哪?
在C++中,不管是基本类型还是类,都可以在栈和堆上
struct MyClass{ int num = 0; } signed main() { // 栈上,也就是在main函数内部的空间里 MyClass m1; int i1 = 100; // 创建的对象在堆内存中,但是提供了一个门牌号给你访问对应的内容 // 但是m2这个指针变量本身还是在栈空间上。 MyClass* m2 = new MyClass; int* i2 = new int(100); return 0; }由这段代码,我们可以有两个认识
- 对象可以在
任何位置,不管是函数的栈空间内,还是在堆内存上 - 在堆内存中的对象,
函数内只有它的指针。但指针这个内容本身,还是一个在栈上的内容
正是这个指针的存在,割裂了我们对用new申请出来内容的认知,也让大部分初学RAII的人对如何运用智能指针产生了犹豫
- RAII要求资源需要绑定到
对象上,用对象的生命周期去管理那片申请出来的资源- 首先,许多初学者只看到了如何编写
构造函数和析构函数这些内容,但是没有认识到,对象才是RAII产生作用的主体! - 其次,既然是对象,那就必须是对象! 是的,这是一句废话!
- 错误的,
这不是一句废话!很神奇对吧。在上面的例子中,尽管我们申请了4个内容,但是只有两个是对象
分别是 MyClass m1; 和 int i1 = 100; 那么另外两个对象在哪呢?
是的,我们根本没 m2和i2指向对象的直接控制权这就是两个破烂牌子,不是对象本身!
- 首先,许多初学者只看到了如何编写
flowchart LR subgraph S[main 作用域] m1[MyClass m1<br/>对象本体] i1[int i1<br/>对象本体] p1[MyClass* m2<br/>指针变量] p2[int* i2<br/>指针变量] end subgraph H[动态存储区] o1[new MyClass<br/>对象本体] o2["new int(100)<br/>对象本体"] end p1 --> o1 p2 --> o2通过以上的讲解,大伙终于发现了盲点,我们一切申请内存得到的内容,都只是指针,而不是对象本身,对象本身不在了,那我们就无法用它的任何内容去进行资源的处理(RAII)
- 之前在
1.3章的3节中,讲过用智能指针进行套娃,套娃的本质就是,我们需要对象!new得到的不是对象,因此我们需要再把它交给一个托管的对象,也就是 std::unique_ptr<Classxxxxx> 对象uuuuu(new Classxxxxx) ,这里唯一有用的只有这个对象uuuuu。正是这个不是指针的美好东西,给了我们一切随意申请空间和资源的权力。
以上的内容我相信可以帮助初学者建立起对RAII的认知,之所以不强调如何对资源进行封装,而是强调对象,是要破除初学者对指针的迷茫和恐惧,一切申请资源却没有直接得到对象的内容,都需要再用智能指针包裹,即使我们申请资源的类本身已经在构造函数和析构函数里对资源进行了封装。当我们认识到了这一点,那么我们就正确知道了何时需要使用智能指针。
2 栈空间和作用域
好吧,虽然标题有作用域,但还是不太想讲
此处不做复杂的讲解,而仅仅是一个简单类比,这个类比对于我们编写vector并理解其思想至关重要。当一个函数被调用时,通常会形成一个新的 栈帧(stack frame)。你可以把它先粗略理解成“这次函数调用专属的一小块工作区”。它里面经常会放这些东西:
- 返回地址等调用信息
- 函数参数
- 局部变量
- 某些临时对象
函数调用提供了一个自动管理的生存边界。对象在这个边界里创建,在边界结束时被清理。 这个边界也就是作用域
函数应该是每一个学习编程的人能够使用到的最简单、无副作用的内容,在这块系统为我们提供的区域中,我们写的内容(不涉及申请资源)会被这块区域自动管理和销毁。我们丝毫没有意识到,在函数中写下 int a = 10; 其中既涉及到使用了空间,又涉及到函数结束后的自动清理。倘若堆内存也有这样的功能,那么程序员在申请内存时将会毫无包袱。
-
得益于离开作用域后自动调用的析构函数,我们得以使用RAII这样的桥梁,链接到管理的堆内存空间中,销毁资源
-
以下是函数栈和vector的相似之处
函数栈模型 vector 模型 函数调用开始,得到一块受管理的生存边界 vector 构造完成,内部得到一块和vector对象绑定的空间 在作用域里声明局部变量 在连续存储里构造元素 作用域结束,局部对象自动析构 vector 析构时,元素自动析构 栈帧整体被回收 底层连续存储被释放 flowchart LR subgraph F[函数作用域] f1[进入作用域] f2[创建局部对象] f3[离开作用域] f4[对象自动析构] f1 --> f2 --> f3 --> f4 end subgraph V[vector 对象] v1[构造 vector] v2[申请一块存储] v3[在槽位上构造元素] v4[析构 vector] v5[元素析构并释放存储] v1 --> v2 --> v3 --> v4 --> v5 endvector需要显式地提供 申请空间 管理内部对象生命周期
栈则自动提供了空间且能够自动管理内部对象生命周期- 函数栈帧通常是这次调用
固定的一块区域;vector 可以扩容、更换区域地址。 - 函数的
自动清理由语言规则提供;vector 的清理由类的构造/析构逻辑提供。 - 栈上的局部对象通常一声明就开始生命周期;vector 可以先只有原始存储,再逐个决定哪些槽位真的构造成对象。
- 当然,得益于RAII,栈空间和vector都能通过调用对象析构函数,销毁对象自己持有的资源。只不过一个是自动,一个需要手动
对于这样的一个内容
// 没有实现RAII struct Vec { Vec(int s) { size = s; data = new int(xxx); } int size; int *data; }; signed main() { Vec v{10}; return 0; }flowchart LR subgraph S[main 作用域] v["Vec v<br/>size: 10<br/>data"] end subgraph H[动态存储区] arr["new int[10] 内存块<br/>(泄漏!)"] end v -- data 指针 --> arr style arr fill:#ffcccc,stroke:#ff0000- 可以看出,直接创建对象,没有使用RAII技术,内存泄漏了
使用RAII后
// 实现RAII struct Vec { Vec(int s) { size = s; data = new int(xxx); } ~Vec() { delete data; } int size; int *data; }; signed main() { Vec v{10}; return 0; }flowchart LR subgraph S[main 作用域] v2["Vec v<br/>size: 10<br/>data<br/>(析构函数自动 delete[])"] end subgraph H[动态存储区] arr2["new int[10] 内存块<br/>(自动释放)"] end v2 -- data 指针 --> arr2 style arr2 fill:#ccffcc,stroke:#00aa00通过
对象和RAII,自动释放了以下是使用RAII,即使使用了new将vec对象放在了堆内存上,但是通过托管,也成功释放了
signed main() { std::unique_ptr<Vec> up(new Vec(10)); return 0; }flowchart LR subgraph S[main 作用域] up["std::unique_ptr<Vec> up<br/>(持有 Vec*)"] end subgraph H[动态存储区] vecobj["new Vec<br/>size: 10<br/>data"] arr3["new int[10] 内存块<br/>(由 Vec 析构释放)"] end up -- 管理 --> vecobj vecobj -- data 指针 --> arr3 style vecobj fill:#ccffcc,stroke:#00aa00 style arr3 fill:#ccffcc,stroke:#00aa00- 双重自动释放:unique_ptr 析构 → delete vecobj → Vec::~Vec() → delete[] arr3,所有资源全部安全回收。
- 以上类比最大程度关注了两者的相似之处。真正的难点在于二者不同的地方。这些不同的内容,也将是这篇文章对于一般的vector教学最大的不同之处。虽然我这个也挺一般的.....
- 对象可以在
-
[新功能]: 论坛支持mermaid代码自动渲染 - 附渲染效果 -
[新功能]: 论坛支持mermaid代码自动渲染 - 附渲染效果 -
从小白的视角探究 vector@dustchens 在 从小白的视角探究 vector 中说:
光讲套壳,这和 vector 又有什么关系呢?深水区来了。
第一节的精髓在于这一段之后的内容。不过我没有给出栈和作用域等内容的讲解。这段内容本身是非常复杂的,但是副作用却很小,小到每个人编程一开始都能无障碍使用。
拿函数来类比vector,就是因为我感觉缺少一个能够切入申请空间和管理生命周期的点,如果说每个人一开始就能写的main函数,是最简化了空间管理和生命周期管理,让你意识不到它的存在,那么vector就是需要我们把这套内容拿到明面上来,且二者的本质是一样的(从空间和生命周期管理的语义来看)
-
从小白的视角探究 vector -
从小白的视角探究 vector -
从小白的视角探究 vector从小白的视角探究 vector
学习C++就像盲人摸象,好吧,其实大部分编程语言的学习都是这样,但是C++还是更难一点,它既有厚重历史又在不断现代化,在现代化的同时又不像Java那样可以抛弃旧版本,直接从一个更新更容易理解的阶段开始学习,知识点散落在不同的地方,摸一摸只能知晓部分。
这篇文章便是我摸不同内容给出的自己的一个浅薄理解,如有错误,也请大伙指正。
1 初识 vector
最小实现
struct DefaultAllocator { public: using Address = unsigned long long; static void * allocate(int bytes) { void *memPtr = ::malloc(bytes); return memPtr; } static void deallocate(void *addr, int bytes) { if (addr == nullptr) { std::exit(-1); }else { ::free(addr); } } }; template <typename T, typename Alloc = DefaultAllocator> class Vector { public: Vector() : mSize_e { 0 }, mDataPtr_e { nullptr } { } Vector(int size) : mSize_e { size } { mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mSize_e)); for (int i = 0; i < mSize_e; i++) { new (mDataPtr_e + i) T(); } } ~Vector() { if (mSize_e) { for (int i = 0; i < mSize_e; i++) { (mDataPtr_e + i)->~T(); } Alloc::deallocate(mDataPtr_e, mSize_e * sizeof(T)); } } private: int mSize_e; T * mDataPtr_e; };这段来自 sunrisepeak 大佬的教学代码,是很多新手小白对
vector的第一印象。
从中既能看出C++继承C的内容,比如熟悉的for循环,又可以窥见C++偏向应用层的截然不同思想。这段简单的vector实现包含了模板、内存分配和构造函数等内容,下面将拆解这段程序,并讲述我自己的理解。。1.1 模板
问题:
template是什么?typename是什么?T又是什么?话说 long long years ago,在西牛贺州的平顶山莲花洞里,有金角大王和银角大王两个妖怪,他们手中有一件来自太上老君的法宝: 紫金葫芦。葫芦有个逆天功能,叫到了名字,回答一声就可以被吸进去顷刻炼化。拿着葫芦叫一声者行孙,猴子就被收了进去。名字就是代号,代号就是名字,在 C++ 的世界中,每一个东西也都有一个名字,这就是类型,比如我们常用的
int。但是如果孙悟空不叫孙悟空,也不叫行者,葫芦是收不进去的。如果要收所有人,就要知道所有人的名字。这显然只有现代人可以实现: 建一个数据库,再配合盒武器。而模板就是这样的武器。
template是使用模板的前置说明。typename说明接下来会有一个叫T的的万能类型。T本质上是一个占位符。
在 C++ 宇宙中,所有基本类型都是确定的,那么由这些基本类型构成的复杂类型也同样可以确定。切换到西游世界,那就是世界上只有三个名字: 孙悟空、孙行者、行者孙。在你使用
vector<者行孙>的那一刻,编译器便帮你生成了对应类型的容器;如果孙悟空拔出毫毛变出一堆孙悟空,那就用一个class包裹,编译器会生成一个vector<class{者行孙*n}>这样类型的容器。这就是模板的用处。由此可见,
T不是万能类型,因为 C++ 宇宙中并没有万能的类型;只是编译器会根据你写下的类型,根据其中的基本元素,帮你推导并生成对应代码。当然,模板和葫芦还是不一样的。收尽所有人确实需要知道所有人的名字,但一个葫芦只能收一种人。在写下类型的那一刻,就会生成一个相应的葫芦,而不是收尽所有人的万能葫芦。这也正是<mark><strong>模板生成代码</strong></mark>的含义。
1.2 内存
问题:为什么需要内存管理?内存管理又和 RAII 思想有什么关联?
1. 为什么需要申请内存
int num = 10; int* ptr = new int(10); int arr1 = int [99999999999999999]; int* arr2 = new int [99999999999999999];对于
num和ptr,目标都是得到一个值为 10 的数字。表面上看两者效果一样,指针甚至还要根据门牌号多找一次,这样看完全是多此一举?- <mark><strong>生命周期</strong></mark>:这是申请内存的第一个需要。
num在函数栈上,会随着函数结束而一同消失;但ptr不一样,ptr本身只是一个门牌号。即使门牌号自己销毁了,在函数栈之外的空间里,系统仍然为你保留了这个 10。倘若其他地方也知道这块门牌号,就都可以进去获取甚至修改内容。 - <mark><strong>空间</strong></mark>:对于 arr1 和 arr2,则引出了申请内存的第二个需要。栈空间是
有限的,C++ 程序无法在栈上稳定地开辟非常巨大的内存;而操作系统为你提供了更大的自由空间,可以让你存放相当大的内容。
仅此而已吗?显然并不是,在申请数组的时候,都确定了大小,那么不知道大小呢
- <mark><strong>灵活</strong></mark>:灵活既关系到空间又关系到生命周期。有时候数组大小并不是一开始就能确定的,程序需要在运行过程中,动态申请一个范围很大的、大小可变的空间。
以上就是申请内存的原因。那么有这么多好处,代价是什么呢?
代价
真正造成代价的原因只有一个:系统并不会为程序收拾烂摊子。
操作系统在你申请内存后,会判定这块内存正在使用,但它并不关心这块内存何时不再需要,也不会主动替你
回收。于是内存泄漏、越界访问、双重释放等一系列问题都由此产生。除此之外, C++ 继承自 C 的指针语义,还给了程序员很大的权力去访问不同的内存地址,甚至超越程序本身的内存,这已经触碰到操作系统的斩杀线了。由此,不同语言走上了两条路:
- 自动内存管理:语言提供一套机制,程序员只管申请,回收交给 GC 或运行时系统。
- 手动管理:内存的一切行为都交给程序员自己控制。
手动控制是好事,但是手动控制是好事不太可能?
C++ 里的
new和delete对应申请与销毁,对于对象而言,他们还有两个额外的操作。一旦你忘了销毁、销毁位置错了、或者流程中途跳出了,问题就很难避免。void memory_leak() { int* data = new int[1000]; // ... 一些处理 ... if (some_condition) { return; // 提前返回,忘记 delete[] } // ... 更多处理 ... delete[] data; // 只有正常路径才执行 } void exception_unsafe() { Foo* obj = new Foo(); Bar* bar = new Bar(); // 若 Bar 构造函数抛异常,obj 泄漏 // ... 可能抛出异常的操作 ... delete bar; delete obj; } void double_free() { int* p = new int(10); int* q = p; // 两个裸指针指向同一资源 delete p; delete q; // 未定义行为:双重释放 }以上可以看出使用指针申请内存的部分问题,这些问题的根源就是之前所说的: 裸指针只是一个门牌号,并不承担任何对申请出来空间的管理责任。一切都需要手动控制。
如果是在古老时代,编程还是少数精英程序员的专属能力,他们对内存和语言掌握得炉火纯青,可以游刃有余地解决手动管理的一系列问题;可是现代编程普及之后,以及软件的复杂度攀升,单纯使用手动管理显然不再适应时代的发展,现在用于大型软件的语言,基本上都必须提供更加简单便捷的内存管理手段。
2. RAII
机制怪来了 不对,是将军来了。原来是 Bjarne Stroustrup 来了,祖师爷的恩情还不完。
RAII原名RAII, 原名Resource Acquisition Is Initialization,<mark><strong>资源获取即初始化</strong></mark>。
它的核心思路是: 用一个栈上对象的生命周期,去绑定对应资源的生命周期。对象进入作用域时拿到资源,对象离开作用域时自动释放资源。如果对象会随着函数栈退出而销毁,那么连带的内存资源也同样销毁。这是现代C++保证内存不泄漏的唯一机制。
这是一个机制怪,C++对于类定义了一系列的特殊函数,而那个随着对象销毁而
自动调用的析构函数显然是最特殊的,对象总有死的那天,伴随死亡的还有一场风光大葬。struct RAII { RAII() { // 申请资源 ptr = new T(); } // 此处省略其他构造函数 ~RAII() { // 释放资源 if(ptr) { delete ptr; } } T* ptr; } { // 资源被包裹在对象内 RAII r1 = xxxx; // 离开作用域自动调用 ~RAII() 销毁 }需要申请内存的资源绑定到对象上,用对象的构造函数去申请资源,然后对象因作用域的销毁自动调用析构函数,销毁申请的资源。这样资源的收尾就被封装进类型本身,不再散落在业务流程里。
但如果包裹资源的对象本身也需要申请内存呢?比如写成
RAII* r = new RAII这样的形式,依旧产生了裸指针的问题。好在 C++ 还提供了继续“套壳”的办法,对裸指针进行托管,也就是智能指针。现代C++管理内存的精髓就在于利用好这个可以自动调用的析构函数,以及相应的构造函数,将资源包裹起来,尽量避免直接使用
new去申请内存,将一切托管。这也要求我们在设计一个持有手动管理资源的类时,必须要考虑如何将一切手动管理封装在类内部,由此引申出3/5/0原则。可以说RAII的思想贯穿了整个现代C++,这种思想也即将应用在我们对于vector的学习之中。1.3 讲解和总结
前几节讲的内容算是一个简单的前置信息,有了这些内容,我们才能对vector有一个简单的理解。
1. 成员
成员 作用 T* mDataPtr_e指向申请空间的指针,且指明了申请的类型 int mSize_e申请空间的大小,后续我们将会对size进行一个解耦 从语义上看,它说明了几件事:
vector内部有自己申请的空间。
且有一个指针指向这块空间的起点。根据 RAII 思想,申请和销毁必须被构造函数和析构函数托管。- 空间大小必须声明。
数组不是指针!如果我们想让vector表现得像数组,必须显式声明大小,因为数组必须包含数量这一本质。哪怕数组在 C++ 中可以用指针访问,如果不关心数量这一核心语义,而去关心用什么实现或者使用,从而得出底层实现等于顶层语义,就是巨大的谬误! - 需要人为划分整块内存,并提供对应操作。
只有这样,才能在一块连续空间上实现数组的语义。
2. 解耦内存操作
mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mSize_e));new (mDataPtr_e + i) T();Alloc::deallocate(mDataPtr_e, mSize_e * sizeof(T));(mDataPtr_e + i)->~T();
以上的内存分配和构造函数、析构函数的调用和新手的印象产生了偏差,new的形式变了,与new配对的delete也不见了,取而代之的是调用了free,还有一堆奇怪的内容,这些云里雾里的东西成了新手的第一道门槛,我称之为new和delete的解耦。
首先先解释一下new和delete的作用:
new- 向内存申请空间,对应底层的
malloc一类动作,大小由size决定。 - 调用构造函数,在C++中,new直接调用了构造函数,这是解耦的关键。
- 向内存申请空间,对应底层的
类比到new,delete同样也是两步操作
delete- 且由于栈的先进后出,new先申请空间再调用构造。delete先调用析构函数,结束对象生命周期。
- 再释放整块空间。
但是即使拆解了new和delete,知道他们分别对应两个步骤,可是为什么要分开来呢,十万个为什么始终在我们初学者的心中萦绕。
土木佬的故事
newer 生活在一个方格世界,所有房屋都是矩形的,占有一个或多个方格,同时建造房屋必须拥有地契。
newer 是个很有能力的人,他既会疏通关系,又是个土木佬,原来是甲方和总包合体了。他的主业是建造房子租给别人住。newer 先找有关部门批了块地契,建了一个地契上规定位置和大小的房子,并招来了租客。
同时他有一个合作伙伴 deleter,专门负责帮他清理那些房租到期的房子: 先通知租客走人,然后炸掉房子,最后去有关部门销毁地契。
某天,newer 突发奇想,想建一排一样的房子,于是他一遍遍地往有关部门跑,每次只批建一个房子的条子,然后回来自己盖。最终这一排房子分散在方格世界的各个地方,本来听说房子都在一起的租客也不愿意住了,于是他破产了。他犯下的第一个错误: 有关部门给的地契,并不挨在同一个地方,整个世界哪里有空就放在哪里。同时还有很多和newer一样的人在申请地契,newer第二次去申请的地方早就被别人占据了。
东山再起后的 newer 变聪明了,这次一次申请了多块连在一起的地契,盖好了一排标准化房子,还给这排房子起名叫公寓。房子租出去不少,但等到有租客房租到期时,deleter 照常通知租客离开,炸掉了房子,又去有关部门销毁这一间房的地契。这回 newer 又破产了,因为整块地都不属于他了。
因为方格世界有两个规则怪谈:
- 地契永远只有一张纸!
- 销毁地契也只能销毁一张!
-
去有关部门申请地契时,一次不管申请多少地契,最终只有一张地契给出。
-
不管地契上是一间房子还是多间房子,因此多间房子的地契无法销毁掉其中一间房屋,只有整个销毁,如果被发现只销毁部分地契,这两个人都会被抹除。
发现这两个规则后,newer 这次申请了一大块连在一起的地,盖一排排房子,而且每个房间都做好了装修,最终newer还是破产了,因为根本没有那么多人租房子了,装修的钱还是借的,入不敷出的newer结束了土木佬悲剧的一生。
这个故事对应了 C++ 里的三条规则:
- 多次
new到的位置不保证相邻。 new申请内存时,位置是不确定的,无法保证多次申请到的位置是相邻的 delete释放的是整块内存,不能只释放其中一部分。- 需要多少内存就申请多少,可以多申请一部分。 但是一开始就申请巨大的内存并且构建是要付出代价的,故事中的租金在操作系统中可能意味着内存频繁换页、分配巨大内存直接失败等问题
那么由这三条规则,可以推导出拆解new和delete的理由:
- 如果直接使用
new T[],一次性申请一大块空间并把对象全都构造出来,这对T有额外要求,而且会造成浪费。这对应了规则3。 vector需要对元素进行精细化操作,比如增加和释放。由规则1可知,内存申请的位置是不确定的,那么就无法做到增加的空间恰好连在整体空间后,由规则2也可知,释放元素也无法做到释放中间位置,因此必须解耦,并提供更基本的操作。
还有很多其他的理由,但是初学者基本只需要知道这些即可。总结起来就是new和delete的两步特性,和vector的需求发生了冲突,vector需要自己管理内存上多个对象的生命周期,而new和delete只能掌控一整块的内存。
精细化管理
根据前文总结,我们可以看出,空间和单个元素生命周期,是vector拆分new和delete的原因,如何拆分也就顺理成章了。
-
空间
mDataPtr_e = static_cast<T *>(Alloc::allocate(sizeof(T) * mSize_e));对应申请空间,operator new(size)。allocate底层调用了malloc,会向内存申请一块大小为sizeof(T) * mSize_e的空间,也就是申请 T 大小的单间,共size个。只申请空间而不调用构造函数!static_cast<T*>malloc申请出来的空间大小确定了。但是如何划分没有确定,也就是整块内存的门牌号是按照void* 空指针去看待的,如果我申请的是10个双人间,但是用别的方式去看,看成了5个4人间,那就出现问题了。static_cast<T*>的作用就是类型转换,将门牌号转换为T*,这样在做指针运算和sizeof的时候,指针能按照正确的步长前进后退。且这个转换是现代C++要求的显式强制转换,而不要使用(T*)(void*)这样的转换。转换方面的知识留给大家自行去了解。。Alloc::deallocate(mDataPtr_e, mSize_e * sizeof(T));对应operator delete(ptr)。deallocate底层调用了free,它只负责释放整块内存,并不关心析构函数。- 可以看到free只需要知道指针(第二个参数根本没有用到),也就是门牌号,就能删除当时创建的内存块,因为系统在分配内存的时候就将大小信息放在了内存块的某处。
-
生命周期
new (mDataPtr_e + i) T();- 这里的
new和普通new不是一个东西,叫做 placement new。它的作用是在指定的已开辟内存位置(mDataPtr_e + i)上,唤醒对应构造函数,也就是后面的T()。在此处对原本空白未初始化的内存进行装修并喊来人,开启对象的生命周期。 (mDataPtr_e + i)->~T()- 这里则是显式调用析构函数,结束对象生命周期,但并不释放整块空间。
3. 总结
相信大部分看到这里的初学者还是会有点懵。
vector作为动态数组,既包含 RAII 思想,又要自己管理内存,套了一层又一层,很难不让人心生畏惧。如何将以上散落的知识进行汇总并充分理解呢?还是拿出小例子吧。// 2 class RAII() { // 代码见上文 } signed main() { // 1 // 手动申请空间,手动释放 int* ptr = new int(10); delete ptr; // 这显然不对,违反了 RAII 的原则,如果内容多了之后手动释放很难不出现问题 // 所以我们开始用一个对象去包裹住这个资源 RAII ra{10}; // 这样做以后,new 操作被包裹进了 ra 对象中 // 一旦 main 结束,析构函数就会自动调用,释放资源 return 0; // 2 // 隐藏的自动调用内容 // ~RAII() 此处完成清理 }既然包裹进了对象中,析构函数会帮我们自动释放资源,那么为什么还是不推荐继续用
new呢?// 接上一段代码 signed main() { // 这样会发生什么呢?我们已知RAII的析构里是有释放资源的代码的 RAII* ra = new RAII{10}; return 0; }好了,我们辛苦写出的析构函数又失效了,因为对象不在我们的main函数里了,它被new申请在了不属于main空间掌控的内存中,而ra从对象变成了指向对象的门牌号!
如果我们确实又有这种需求怎么办?装载资源的对象本身就非常大,我们就是要搞个大房子呢?
RAII 思想套壳来了。 既然执意还要搞个空间,那就再套一层吧。
struct RAIIRAII() { RAIIRAII(int val) { ptr = new RAII(val); } ~RAIIRAII() {if(ptr) delete ptr;} RAII* ptr; } signed main() { // RAII* ra = new RAII{10}; // 好了,灾难终于解决了 RAIIRAII rara {10}; return 0; }这层不断套壳的操作,可以最大程度避免直接使用裸指针申请资源;再套壳的操作,就是智能指针的思路。
光讲套壳,这和
vector又有什么关系呢?深水区来了。我们由上文可以看出,RAII 思想要求用对象生命周期去解决内存资源的自动释放问题;同时,
vector也要求精细化管理内部元素的生命周期。都是生命周期,在哪里有区别吗?显然,是没有的。signed main() { int a = 10; RAIIRAII rara {10}; char str[] = "hello world"; vector<int> vec; return 0; }我们随手写出的
a、rara、str、vec,他们在main的函数栈中,都会随着函数结束,而被杀死。只不过a是一个int,直接捅死;rara这样的对象则需要先找析构函数,然后再杀死。甚至我们写出的裸指针,裸指针这块门牌号本身,也会被杀死,只不过只有通过RAII技术,才能自动调用析构函数去销毁门牌号对应的房间资源。
那么我们继续思考以下的代码:
struct vector{ vector() { arr[0] = 0; } arr[10]; } signed main() { int arr[10]; arr[0] = 0; vector vec; return 0; }倘若
vector是这样的,那这两个数组的生命周期其实并没有本质区别,vec会随着main结束而销毁。等等, 倘若我们把
main函数也看成是一个类呢?main提供了栈空间,让我们能随心所欲地创建 int a 这样的小内容而不用new去申请更大的内存;同时main结束时又把这些内容全部清理掉。这和调用析构函数去清理有什么本质区别吗?我们使用 RAII 去包裹资源,只是因为这个资源在更远的地方,我们只知道门牌号。而我们在
函数里随便使用的各种对象、基本类型,函数这个“类” 既知道门牌号,而且资源就存储在类里,所有函数(或者说作用域)能清理掉绑定在它身上的变量和对象。而这个“mian类”在
退出的时候,又向系统归还了它的栈空间,好像我们发现了什么东西!这和我们要实现的vector在本质上不是一样的吗?我们提供了一块空间(从内存申请来的),同时我们希望在内部能够随心所欲地添加相同类型的对象,这和我们在main函数里写的那些变量不是一样的吗?然后vector需要和函数一样,清理掉绑定在它身上的对象,在退出时清理掉申请来的空间。
我们初学者之所以觉得这些内容难以理解,就是因为这些机制太普遍了,普遍到我们根本没有意识到它的存在。我们需要意识到,内存空间都是一样的,并不因为我们用new申请了资源,申请到的空间和我们在函数中使用的空间有什么本质区别。
看到这里,我相信和我一样的初学者会对vector对内存的管理会有一个初步的了解。以下就是我个人总结的后续学习vector的一些认知
以下是我个人总结的几个关键认知:
- vector 需要我们模仿函数栈,只不过是需要申请大块的空间(栈空间有限)同样要用RAII管理这块空间。同时我们需要对这块空间上创建的对象进行管理,至少在vector消亡的那一刻需要将他们全部带走
- 既然是全部带走,那么我们就必须要求元素类型本身实现了对资源的保护!即使标准本身没有这样说明,但是如果类型本身携带资源,且没有实现RAII,那么vector不会为你解决这些问题,就像函数栈没有义务清理裸指针申请出来的内存空间一样。
- 细微的不同在于,我们申请的这个空间可以调整大小,而不像函数栈一样有最大限制。同时因为可以调整大小,再根据我们之前讲过的无法申请到相邻内存的原则,我们必须释放掉当前的内存块,申请一个更大的新内存,这也是扩容的基础思想。
2 改进 vector,实现 Big5
// TODO 后续再发
感谢
- 本文代码的核心框架来自 bilibili LH_Mouse大佬的视频。
- 同时也参考了 sunrisepeak 大佬的代码和视频: BV1K1421z7kt。且本文大部分讲解代码直接用的对应的教学文档代码。
-
项目想法: mcpp-start: 完全0基础的现代C++社区教程项目 - 想法讨论感觉学习最难的地方就是内容太分散了,而且夹杂了很多和语言本身不相关的内容,可以说相关也可以说不相关,我的用词不一定准确。
如果只限定C++20以上版本。完全用模块,且限定一种编译器,使用cmake,那入门的难度会降不少,但是中间还是有鸿沟,如果不能完全理解其中的历史包袱,还有大量使用,会非常难学。
拿教培最成功的Java来说,初期学习很大程度是倾向于了解语言本身语法,还有一些实现特性,比如各种容器怎么用,特性背后是什么原理,IDEA一开,按钮点一点就可以了,并且出现问题也很容易定位错误,反正大伙都是随地大小抛异常的,叫什么名一清二楚。再深入一点,要学习各种轮子是怎么写的,ctrl按住鼠标点一点就跳进了源代码,源码非常清晰,顶多长了一点复杂了一点,抄也很容易抄明白。到了深入学习的时候,开始学习项目框架,多线程这些,再引入三方库,基本上很容易操作。最后的最后,哪怕学习不明白,了解的不够深入,也有spring这样的大杀器,它的原理很复杂,但是使用却很简单不同层级上@几下,很快就能搭建一个破烂项目,虽然很破烂,但是它跟高级项目是同一个东西,恭喜你,没有入门也半只脚踏进去了。
但是C++不一样,一起跟它出现的是C,那就引出了无数的历史包袱,想要入门,门在哪里就成了一个问题,门在水面下,很多东西是以思想的形式存在的,并且一些新特性,本身就是散开的,都是为了解决之前分散在不同方面的问题,学了知道了但是不知道在哪串起来。
第一个要学的就是内存管理的思想,为什么说是思想,而不是方法。我认为编程语言就是一步步抽象的过程,为什么要抽象,是因为要实现功能,很多写C的老保觉得底层更高级,以至于衍生出多汇编吹,不是这样的,计算机最终目的是实现人想要实现的东西,这个实现才是有意义的,编程语言实现的是语义,语义经过计算机执行得到结果,语义是我们书写最重要的东西。用什么汇编实现,底层到底怎么样,是次要矛盾!如果它是主要矛盾,那么大伙都应该在用 0 1实现语义才对,哪轮得到汇编,正因如此,表达语义更简单的汇编取代了打纸带写01,高级语言用更方便的语义表达让程序员能更好工作,AI也提供了用自然语言表达语义得到计算结果的能力。只不过我们这个领域大部分功能还是需要我们用编程语言实现语义,得到结果,或许几百年后编程可以用自然语言,直接通过更高级的编译器翻译成C++或者其他语言再变成机器码实现语义,得到程序。
扯远了。。。。内存管理是一种思想,因此用虚拟机管理内存和手动管理内存,并没有本质的区别,只是实现不同,效果有略微差别罢了。C++处于一种半自动管理的状态,这个半自动是指相比于纯C,语言本身的机制自动帮你实现了部分管理内存的语义,RAII的思想就是这个半自动的衍生品。内存管理这部分要让新手能入门,就不能只讲构造析构,还有智能指针这些,而是要给出对应C语言在原始手动状态,是如何实现的,这样才能完全明白原理。
就比如智能指针,它实现内存管理是借助了析构函数这个能在离开作用域自动调用的特性,相同的C语言代码,要借助一系列黑魔法才能实现同样的语义,给出这些代码有了对比就能更好讲解,让大伙知其所以然。
再比如各种vector轮子的讲解,初学的时候一头雾水,为什么要用什么allocate和定位new,这时候把C实现new的代码贴出来,(先申请个空间,强转一下;对不同类型赋值,有的还需要再申请资源)这就又把new和delete是两件事的知识点再串起来了,然后又能引出这样拆分的好处:预先分配大块内存,定位new可以在指定位置用构造函数赋值。而主动调用析构,也就是通知房子空了,里面可能存在的资源也清理了。如果不拆分,那调用delete,就会把大块内存中间删掉一个内存,释放给操作系统,还要维护断开不连续的两个内存。如果项目能以一种思想的实现串连起分散的内容,或者按片划分,那对于学习真的很有帮助。然后就是各种历史遗留问题,enum、头文件本质是复制粘贴,其实就是那时候编译器不太智能硬件各种受限,导致后续一系列。。。。然后还要讲几个编译器,cmake,包管理,这些感觉都不是语言本身要学习的,而是历史遗留不得不学,讲解cmake这些东西,那就要对比着来,比如在vs里添加各种链接,才能体现有这么个配置文本的好处。扯不出来了,总之这些历史遗留和基础设施,弗如rust。后续建议扯不出来了
-
dsx自动检测出现错误 -
dsx自动检测出现错误@SPeak 大概定位到了问题,在我当前的代码下,slist.2.cpp里的 // d2ds::SLinkedList<int> intList2(intList1); 这些拷贝语句都会使得无法进入该练习
https://github.com/dustchens/my-d2ds/tree/main/dslings/exercises/linked-list
这是我出错的仓库链接 -
dsx自动检测出现错误 -
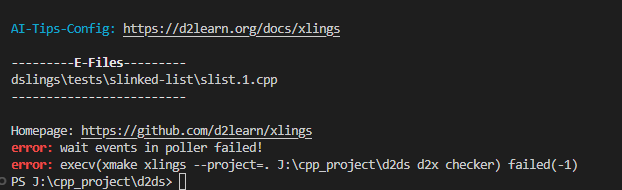
dsx自动检测出现错误删除main之前在 .xlings里执行命令的完整输出
xmake xlings -D --project=. J:\cpp_project\d2ds d2x checker ✅ Successfully ran dslings\tests\dslings.0.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- 🌏Progress: [===>----------------------------------------------] 3/49 [Target: 0-dslings-B-1] - normal ✅ Successfully ran dslings\tests\dslings.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | mVal.get() == 2 (2 == 2) 🌏Progress: [====>---------------------------------------------] 4/49 [Target: 0-dslings-B-2] - normal ✅ Successfully ran dslings\tests\dslings.2.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | mVal.get() == 2 (2 == 2) [D2DS LOGI]: - ✅ | mVal.get() == 2 (2 == 2) 🌏Progress: [=====>--------------------------------------------] 5/49 [Target: 1-array-A-0] - normal ✅ Successfully ran dslings\useage\array\array.u0.cpp 🎉 The code is compiling! 🎉 🌏Progress: [======>-------------------------------------------] 6/49 [Target: 1-array-B-0] - normal ✅ Successfully ran dslings\tests\array\array.0.cpp 🎉 The code is compiling! 🎉 🌏Progress: [=======>------------------------------------------] 7/49 [Target: 1-array-B-1] - normal ✅ Successfully ran dslings\tests\array\array.1.cpp 🎉 The code is compiling! 🎉 🌏Progress: [========>-----------------------------------------] 8/49 [Target: 1-array-B-2] - normal ✅ Successfully ran dslings\tests\array\array.2.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | BigFiveTest::destructor() [D2DS LOGI]: - ✅ | BigFiveTest::copy_assignment() [D2DS LOGI]: - ✅ | BigFiveTest::move_assignment() 🌏Progress: [=========>----------------------------------------] 9/49 [Target: 1-array-B-3] - normal ✅ Successfully ran dslings\tests\array\array.3.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr[0] == 5 (5 == 5) 🌏Progress: [==========>---------------------------------------] 10/49 [Target: 1-array-B-4] - normal ✅ Successfully ran dslings\tests\array\array.4.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | i == intArr[i] (0 == 0) [D2DS LOGI]: - ✅ | i == intArr[i] (1 == 1) [D2DS LOGI]: - ✅ | i == intArr[i] (2 == 2) [D2DS LOGI]: - ✅ | i == intArr[i] (3 == 3) 🌏Progress: [===========>--------------------------------------] 11/49 [Target: 1-array-B-5] - normal ✅ Successfully ran dslings\tests\array\array.5.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr.begin() != intArr.end() [D2DS LOGI]: - ✅ | data == val (0 == 0) [D2DS LOGI]: - ✅ | data == val (1 == 1) [D2DS LOGI]: - ✅ | data == val (2 == 2) 🌏Progress: [============>-------------------------------------] 12/49 [Target: 1-array-B-6] - normal ✅ Successfully ran dslings\tests\array\array.6.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr[0] == intArr[-4] (100 == 100) [D2DS LOGI]: - ✅ | intArr[1] == intArr[-3] (50 == 50) 🌏Progress: [=============>------------------------------------] 13/49 [Target: 2-vector-B-0-0] - normal ✅ Successfully ran dslings\tests\vector\vector.0.0.cpp 🎉 The code is compiling! 🎉 🌏Progress: [==============>-----------------------------------] 14/49 [Target: 2-vector-B-0-1] - normal ✅ Successfully ran dslings\tests\vector\vector.0.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings\tests\vector\vector.0.1.cpp:24 - StackMemAllocator: try to allocate 4 bytes 🌏Progress: [===============>----------------------------------] 15/49 [Target: 2-vector-B-0-all] - normal ✅ Successfully ran dslings\tests\vector\vector.0.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings\tests\vector\vector.0.cpp:19 - StackMemAllocator: try to allocate 10 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 24 bytes [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::allocate_counter() == 1 (1 == 1) 🌏Progress: [================>---------------------------------] 16/49 [Target: 2-vector-B-1-0] - normal ✅ Successfully ran dslings\tests\vector\vector.1.0.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 4 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001a86f578f80, bytes 4 🌏Progress: [=================>--------------------------------] 17/49 [Target: 2-vector-B-1-1] - normal ✅ Successfully ran dslings\tests\vector\vector.1.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: - ✅ | BigFiveTest::copy_constructor() [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001cc22a81790, bytes 20 [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001cc22a817f0, bytes 20 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001cc22a819b0, bytes 20 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001cc22a81770, bytes 20 🌏Progress: [==================>-------------------------------] 18/49 [Target: 2-vector-B-1-2] - normal ✅ Successfully ran dslings\tests\vector\vector.1.2.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 40 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001a914b20e50, bytes 20 [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::allocate_counter() == 2 (2 == 2) [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001a914b21070, bytes 40 [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::deallocate_counter() == 2 (2 == 2) [D2DS LOGI]: - ✅ | BigFiveTest::self_assignment() 🌏Progress: [===================>------------------------------] 19/49 [Target: 2-vector-B-1-all] - normal ✅ Successfully ran dslings\tests\vector\vector.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 4 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2ff8fa0, bytes 4 [D2DS LOGI]: - ✅ | BigFiveTest::destructor() [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: - ✅ | BigFiveTest::copy_constructor() [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe1040, bytes 20 [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe11c0, bytes 20 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe13c0, bytes 20 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe13a0, bytes 20 [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 20 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 40 bytes [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe1060, bytes 20 [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::allocate_counter() == 2 (2 == 2) [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 00000179b2fe0f30, bytes 40 [D2DS LOGI]: - ✅ | 2 == d2ds::DefaultAllocator::deallocate_counter() (2 == 2) [D2DS LOGI]: - ✅ | BigFiveTest::self_assignment() 🌏Progress: [====================>-----------------------------] 20/49 [Target: 2-vector-B-2] - normal ✅ Successfully ran dslings\tests\vector\vector.2.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr1.empty() [D2DS LOGI]: - ✅ | intArr2.size() == 10 (10 == 10) 🌏Progress: [=====================>----------------------------] 21/49 [Target: 2-vector-B-3-0] - normal ✅ Successfully ran dslings\tests\vector\vector.3.0.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr1.capacity() == intArr2.capacity() (0 == 0) [D2DS LOGI]: - ✅ | intArr1.size() == intArr2.capacity() (0 == 0) [D2DS LOGI]: - ✅ | intArr.capacity() == 10 (10 == 10) [D2DS LOGI]: - ✅ | intArr.capacity() == 4 (4 == 4) [D2DS LOGI]: - ✅ | intArr1.capacity() == intArr2.capacity() (4 == 4) [D2DS LOGI]: - ✅ | intArr3.capacity() == intArr2.capacity() (4 == 4) [D2DS LOGI]: - ✅ | intArr1.capacity() == 0 (0 == 0) [D2DS LOGI]: - ✅ | intArr2.capacity() == 10 (10 == 10) 🌏Progress: [======================>---------------------------] 22/49 [Target: 2-vector-B-3-all] - normal ✅ Successfully ran dslings\tests\vector\vector.3.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: - ✅ | intArr[0] == 1 (1 == 1) [D2DS LOGI]: - ✅ | intArr.capacity() == 2 (2 == 2) [D2DS LOGI]: - ✅ | intArr[1] == 2 (2 == 2) [D2DS LOGI]: - ✅ | intArr[2] == 3 (3 == 3) [D2DS LOGI]: - ✅ | intArr.size() == 3 (3 == 3) [D2DS LOGI]: - ✅ | intArr.capacity() == 4 (4 == 4) [D2DS LOGI]: - ✅ | intArr[1] == 2 (2 == 2) [D2DS LOGI]: - ✅ | intArr[0] == 1 (1 == 1) [D2DS LOGI]: - ✅ | intArr.capacity() == 8 (8 == 8) [D2DS LOGI]: - ✅ | intArr[intArr.size() - 1] == 2 (2 == 2) 🌏Progress: [=======================>--------------------------] 23/49 [Target: 2-vector-B-4] - normal ✅ Successfully ran dslings\tests\vector\vector.4.cpp 🎉 The code is compiling! 🎉 🌏Progress: [========================>-------------------------] 24/49 [Target: 2-vector-B-5] - normal ✅ Successfully ran dslings\tests\vector\vector.5.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- 🌏Progress: [=========================>------------------------] 25/49 [Target: 3-embedded-slist-B-0] - normal ✅ Successfully ran dslings\tests\embedded-list\embedded-slist.0.cpp 🎉 The code is compiling! 🎉 🌏Progress: [==========================>-----------------------] 26/49 [Target: 3-embedded-slist-B-1] - normal ✅ Successfully ran dslings\tests\embedded-list\embedded-slist.1.cpp 🎉 The code is compiling! 🎉 🌏Progress: [===========================>----------------------] 27/49 [Target: 3-embedded-slist-B-2] - normal ✅ Successfully ran dslings\tests\embedded-list\embedded-slist.2.cpp 🎉 The code is compiling! 🎉 🌏Progress: [============================>---------------------] 28/49 [Target: 3-embedded-slist-B-3] - normal ✅ Successfully ran dslings\tests\embedded-list\embedded-slist.3.cpp 🎉 The code is compiling! 🎉 🌏Progress: [=============================>--------------------] 29/49 [Target: 3-embedded-slist-B-4] - normal ✅ Successfully ran dslings\tests\embedded-list\embedded-slist.4.cpp 🎉 The code is compiling! 🎉 🌏Progress: [==============================>-------------------] 30/49 [Target: 4-slinked-list-B-0] - normal ✅ Successfully ran dslings\tests\slinked-list\slist.0.cpp 🎉 The code is compiling! 🎉 🌏Progress: [===============================>------------------] 31/49 [Target: 4-slinked-list-B-1] - normal ✅ Successfully ran dslings\tests\slinked-list\slist.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 16 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 16 bytes [D2DS LOGI]: allocate: dslings/common/common.hpp:64 - DefaultAllocator: try to allocate 16 bytes [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::allocate_counter() == 3 (3 == 3) [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001d6a91d1270, bytes 16 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001d6a91d11b0, bytes 16 [D2DS LOGI]: deallocate: dslings/common/common.hpp:73 - DefaultAllocator: free addr 000001d6a91d14f0, bytes 16 [D2DS LOGI]: - ✅ | d2ds::DefaultAllocator::allocate_counter() == d2ds::DefaultAllocator::deallocate_counter() (3 == 3) AI-Tips-Config: https://d2learn.org/docs/xlings ---------E-Files--------- dslings\tests\slinked-list\slist.1.cpp ------------------------- Homepage: https://github.com/d2learn/xlings error: wait events in poller failed!删除main里的内容之后再次执行的输出
xmake xlings -D --project=. J:\cpp_project\d2ds d2x checker ✅ Successfully ran dslings\tests\dslings.0.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- 🌏Progress: [===>----------------------------------------------] 3/49 [Target: 0-dslings-B-1] - normal ✅ Successfully ran dslings\tests\dslings.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- 🌏Progress: [==============================>-------------------] 30/49 [Target: 4-slinked-list-B-1] - normal ✅ Successfully ran dslings\tests\slinked-list\slist.1.cpp 🎉 The code is compiling! 🎉 🌏Progress: [===============================>------------------] 31/49 [Target: 4-slinked-list-B-1] - normal ✅ Successfully ran dslings\tests\slinked-list\slist.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- AI-Tips-Config: https://d2learn.org/docs/xlings ---------E-Files--------- dslings\tests\slinked-list\slist.1.cpp ------------------------- Homepage: https://github.com/d2learn/xlings error: wait events in poller failed!删掉config.xlings里 checker 的 vscode,在终端中运行的输出依旧一致
🌏Progress: [===============================>------------------] 31/49 [Target: 4-slinked-list-B-1] - normal ✅ Successfully ran dslings\tests\slinked-list\slist.1.cpp 🎉 The code is compiling! 🎉 ---------C-Output--------- AI-Tips-Config: https://d2learn.org/docs/xlings ---------E-Files--------- dslings\tests\slinked-list\slist.1.cpp ------------------------- Homepage: https://github.com/d2learn/xlings error: wait events in poller failed!观察了一下xmake build,结束slist.1.cpp 要运行下一个的时候,cpu占用率迅速提升了,本来只有5-6这样,然后提升到了18,然后等待一段时间,大概十几秒二十秒,结束的时候内存占用从60mb突然提升到200多然后结束
-
dsx自动检测出现错误 -
dsx自动检测出现错误 -
dsx自动检测出现错误
 才发现没有高亮
才发现没有高亮